Why Most SaaS Rewrites Fail (and What to Do Instead)
The decision to rewrite a SaaS platform is rarely made lightly. It comes after months—sometimes years—of mounting frustration: legacy code that resists change, technical debt that slows every release, architecture that no longer fits the product vision.
The logic feels sound. Start fresh. Build it right this time. Apply lessons learned. Use modern frameworks. Eliminate the accumulated cruft.
But most rewrites fail. Not because teams lack skill or commitment, but because the premise is flawed.

The Problem With Starting Over
A rewrite assumes you can capture all existing functionality, all business logic, all edge cases, and all undocumented behavior in a new system—while also improving architecture, performance, and maintainability.
This assumption underestimates the complexity embedded in production systems. Over time, platforms accumulate thousands of small decisions: how data is validated, how errors are handled, how integrations behave under failure conditions. Much of this knowledge is not documented. It exists in code, in team memory, and in production behavior.
A rewrite discards this accumulated knowledge. What looks like technical debt is often institutional memory encoded in software.

Why Rewrites Introduce Risk
Rewrites operate under a critical constraint: the existing system must continue running. Users depend on it. Revenue depends on it. The business cannot pause while engineering rebuilds the platform.
This creates a dual-maintenance burden. The old system still requires bug fixes, security patches, and support. The new system requires development, testing, and integration. Both demand attention. Both consume resources.
Timelines stretch. Scope expands. The gap between "feature parity" and "production ready" widens. Eventually, the rewrite becomes its own form of technical debt—unfinished, under-resourced, and too expensive to abandon.
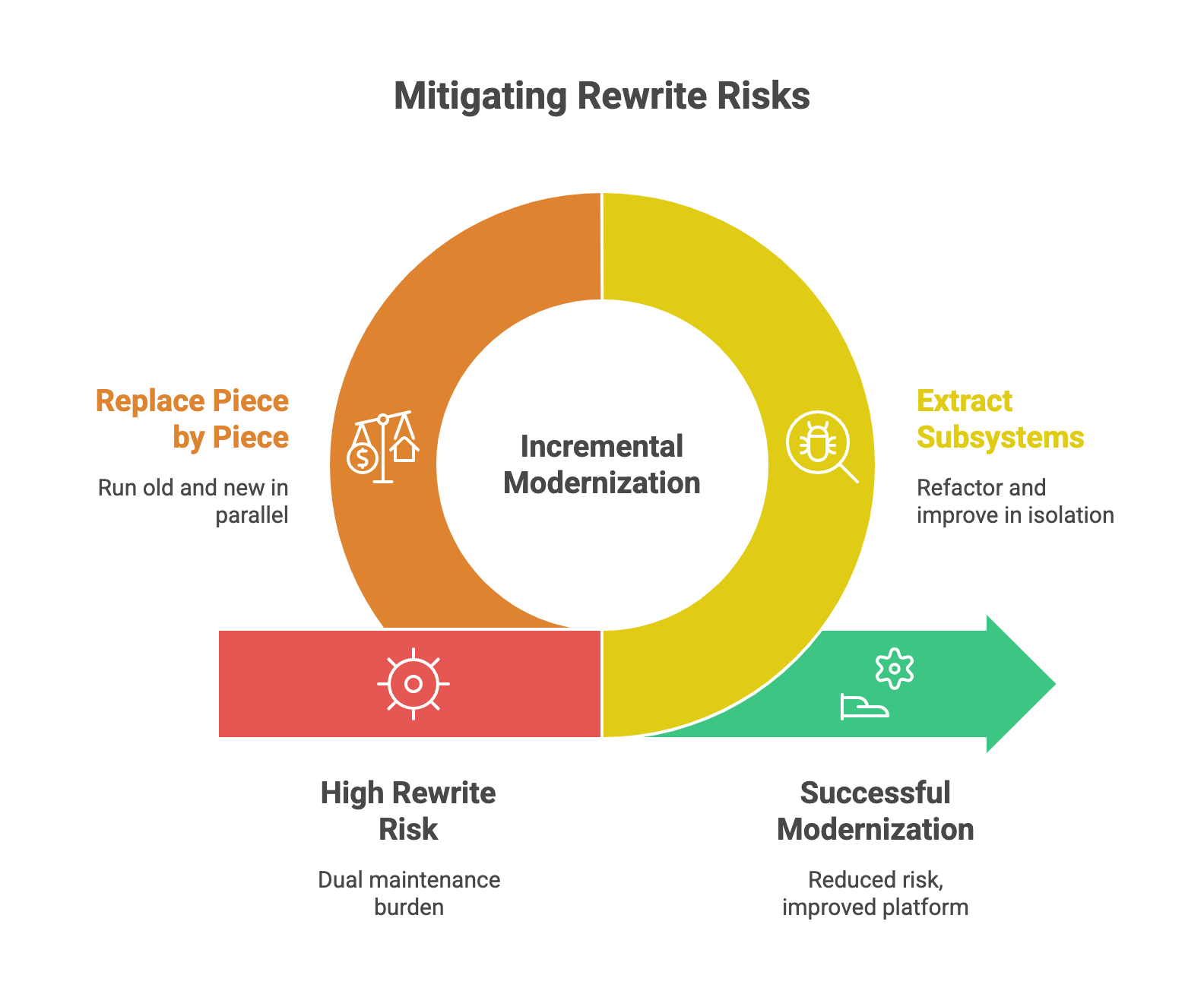
What Works Instead
Incremental modernization. Not as dramatic. Not as satisfying. But far more likely to succeed.
Instead of replacing the entire platform, identify high-value subsystems that can be extracted, refactored, and improved in isolation. Start with the parts of the codebase that cause the most friction: the modules that slow down every feature, the components that break most often, the integrations that fail under load.
Modernize these incrementally. Replace them piece by piece. Run the old and new systems in parallel until the new version proves itself in production. Only then cut over fully.
This approach preserves continuity. It reduces risk. It delivers value continuously rather than deferring it until some distant launch date. And it allows the team to learn—adjusting architecture, tooling, and process based on real production feedback.

When a Rewrite Is the Right Answer
There are exceptions. If the platform is fundamentally unsalvageable—built on deprecated technology with no upgrade path, or so structurally broken that every change breaks three other things—a rewrite may be unavoidable.
But even then, the approach matters. Scope it narrowly. Deliver it incrementally. Prove each component in production before moving to the next. Treat the rewrite not as a single project, but as a controlled migration with fallback plans at every stage.

The Cost of Getting It Wrong
Failed rewrites do not just waste time and budget. They damage team morale, erode stakeholder trust, and leave the platform in a worse state than before—now burdened with both the old system's debt and the unfinished new system's complexity.
The decision to rewrite should be made with full awareness of what can go wrong. And in most cases, the better path is not to start over, but to evolve deliberately.