Release Discipline in Production Systems: What Actually Matters
April 7, 2026
8
min read
Delivery Safety
In mature production systems, release discipline is often misunderstood as process overhead or deployment ceremony. In practice, it is one of the clearest indicators of platform maturity. Strong release discipline reduces avoidable risk, improves delivery confidence, and helps teams change live systems without turning every release into an operational event.
In production systems, release discipline is often discussed as if it were mainly a question of speed.
How fast can we deploy? How often can we push? How much of the process can we automate?
Those questions matter, but they are not the center of the issue.
In live production environments, release discipline is really about how safely a system can absorb change.
That is a different standard.
A mature team is not defined by how quickly it can move code into production. It is defined by how consistently it can introduce change without creating avoidable instability, hidden rollback problems, late-night coordination, or downstream surprises for operations, support, customers, and the business itself.
That is why release discipline matters far beyond CI/CD mechanics. It sits at the intersection of architecture, operational readiness, dependency control, and decision quality.
For teams dealing with aging platforms, integration-heavy workflows, or fragile delivery patterns, release discipline is often one of the clearest signals that the platform has outgrown its earlier operating model.
And in many cases, improving it does more for delivery confidence than adding another tool ever will.
The Mistake Most Teams Make
A lot of teams treat release discipline as a deployment process problem.
They focus on pipeline steps, approval layers, release meetings, or automation coverage. Those things are not irrelevant. But they are rarely the root issue on their own.
The deeper problem is that weak release behavior usually reflects weak change behavior.
The release becomes stressful because the change set is too large. The rollback path is unclear. The system dependencies are poorly understood. The environment behavior is inconsistent. The monitoring signals are incomplete. The ownership model is fuzzy. The timing is driven by pressure rather than readiness.
In other words, the deployment event becomes risky because the surrounding system is already difficult to reason about.
That is why mature release discipline cannot be reduced to “better DevOps hygiene” alone. It has to be understood as a platform operating capability.
This is also where release discipline connects directly to broader platform modernization work. In fragile systems, release pain is rarely isolated. It is usually a symptom of deeper architecture and delivery constraints.
Release Discipline Starts Before Deployment
The strongest release processes usually look calm because the difficult thinking has already happened before the deploy window opens.
By the time a change is ready to ship, the team should already understand:
what is changing
what depends on it
what could fail
how failure will be detected
what happens if it must be reversed
who owns the response if something degrades
That is the real work.
Production discipline is not mainly a checklist at the end. It is the quality of preparation around change.
This is why some teams with highly sophisticated tooling still experience chaotic releases, while other teams with simpler tooling release with much more control. The difference is rarely just the pipeline. It is the predictability of the system and the discipline of the operating model around it.
What Actually Matters
1. Smaller, More Reversible Changes
The first thing that matters is change size.
Large release bundles increase uncertainty. They widen the blast radius, make diagnosis harder, complicate rollback, and force teams to untangle multiple possible causes under pressure.
Smaller releases do not remove risk entirely, but they localize it.
When a production system can absorb smaller, better-scoped changes, several things improve at once:
validation gets easier
rollback becomes more realistic
dependency review becomes more manageable
incident triage becomes faster
release confidence improves over time
This is where release discipline overlaps with architecture. Monolithic change patterns often reflect tightly coupled systems, unclear boundaries, or habits formed when the platform was smaller. Mature release discipline pushes the organization toward cleaner seams and more deliberate change isolation.
Not every platform can move instantly to highly granular releases. But every production system benefits from making changes more understandable and more reversible.
2. Rollback Must Be Designed, Not Assumed
A surprising number of teams talk about rollback as if it exists automatically.
It usually does not.
A true rollback path means the team has already thought through how the system will behave if the release must be reversed. That includes not only application code, but also configuration, schema changes, queued jobs, external integrations, cache behavior, feature flags, and user-facing state transitions.
This is where many releases become dangerous. The code may be easy to revert, but the runtime consequences are not.
A team with strong release discipline does not wait until failure to discover that rollback is partial, slow, or operationally messy. It treats reversibility as part of release design.
That is especially important in platforms with customer workflows, financial implications, messaging infrastructure, operational records, or integration-sensitive behavior. In those environments, rollback failure is not just a developer inconvenience. It can create downstream business confusion that is much harder to unwind.
Writing
A practical checkpoint
If a team says it can rollback, but has not explicitly tested how rollback behaves across schema changes, background processing, third-party side effects, and configuration drift, it does not really have a rollback strategy. It has a hope.
At this stage in the article, it also makes sense to connect readers to your Platform Audit & Roadmap, because release instability is often a sign that the problem is broader than deployment mechanics.
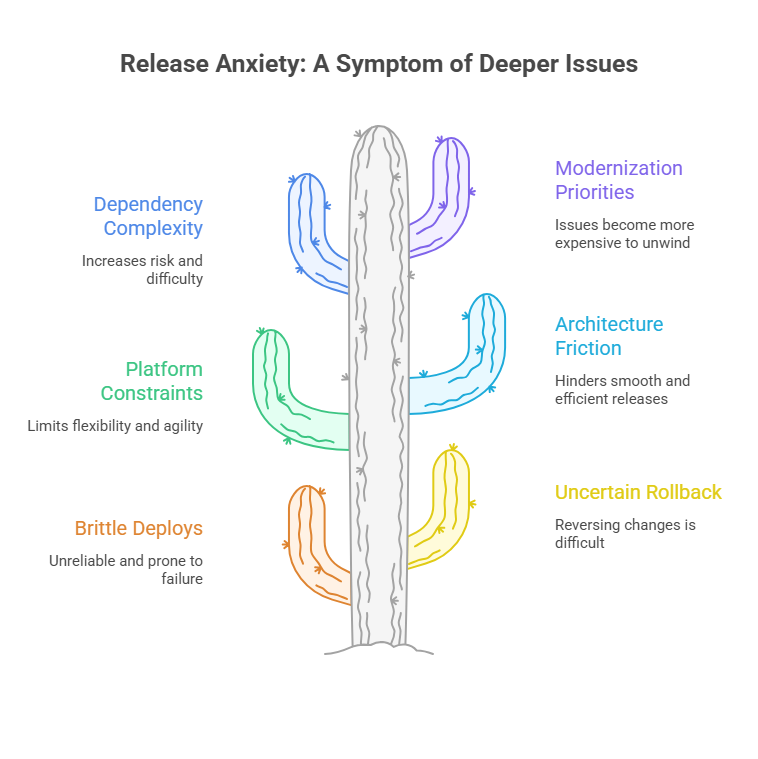
Release anxiety is rarely just a release problem.
If your team is dealing with brittle deploys, uncertain rollback paths, or growing hesitation around production change, that usually points to deeper platform constraints. Platform Audit & Roadmap
helps engineering leaders assess release risk, architecture friction, dependency complexity, and modernization priorities before those issues become more expensive to unwind.
3. Dependency Visibility Matters More Than Ceremony
A release can look fully approved and still be poorly controlled.
One of the biggest sources of release instability is hidden dependency behavior.
This shows up when:
one service change quietly affects another
an integration contract changes without enough validation
a scheduled job behaves differently after deployment
a background process consumes data in an unexpected order
an external provider reacts differently under production timing or load
a customer-facing workflow depends on operational steps nobody included in the release plan
These are not edge cases in mature systems. They are normal failure modes in platforms that have accumulated complexity over time.
That is why real release discipline requires dependency visibility. Teams need a clearer picture of what else the change touches, who relies on it, and where production behavior can diverge from local assumptions.
In many organizations, this is also where enterprise integration work and release control start to overlap. Integration fragility often shows up first during release, because that is when assumptions are finally tested against live dependencies.
4. Environment Parity and Configuration Control
A release is only as predictable as the environment it lands in.
If the production environment behaves materially differently from staging, if configuration is inconsistent, if secrets handling is fragmented, or if infrastructure drift has accumulated quietly over time, then even a well-reviewed change can behave in surprising ways.
Teams often talk about production incidents as if the code introduced the problem. In reality, some failures are really environment mismatches that only become visible during deployment.
Release discipline improves when the team reduces those unknowns.
That means:
clearer configuration ownership
stronger environment consistency
more deliberate infrastructure change control
better understanding of runtime dependencies
tighter handling of feature flags and release toggles
fewer “it worked everywhere else” surprises
This is one reason cloud modernization needs to be sequenced carefully. A move in hosting or deployment model can improve some capabilities while making hidden inconsistencies much more visible. That is why cloud migration strategy should be treated as a control and sequencing decision, not as a badge.
5. Observability Has To Support Release Decisions
Monitoring is often discussed as an operations topic.
In practice, it is central to release discipline.
A team cannot manage production change well if it does not know quickly whether the system is behaving normally after deployment.
Good observability is not about collecting more dashboards. It is about making post-release behavior legible enough to support real decisions.
After a release, the team should be able to answer:
Did the critical path behave as expected?
Did latency or error patterns change?
Did background workloads degrade?
Did integration failures increase?
Did operational workflows slow down?
Did user behavior reveal hidden edge cases?
Without that visibility, release decisions become guesswork. Teams either roll forward blindly, rollback too late, or create unnecessary anxiety because they lack trustworthy feedback.
In that sense, observability is part of release governance. It closes the loop between change and consequence.
6. Ownership and Operational Readiness
Another thing that matters is role clarity.
In weak release environments, everyone is vaguely involved and nobody is clearly accountable. Engineering, operations, QA, support, product, and leadership may all have fragments of the picture, but not enough shared clarity about who decides, who verifies, who communicates, and who responds if something drifts.
Strong release discipline does not mean bureaucratic escalation. It means the operating model is clear enough to function under pressure.
That includes:
release ownership
go/no-go decision authority
rollback authority
communication expectations
incident response readiness
support and customer-impact awareness
handoff clarity across engineering and operations
This matters even more in systems that affect revenue, customer communications, regulated workflows, or business-critical operations. In those environments, weak ownership turns small release issues into broader trust issues.
7. Timing Is Part of Discipline
A technically valid release can still be poorly timed.
This is often ignored.
Production systems exist inside business rhythms: billing cycles, customer support load, partner processing windows, seasonal spikes, end-of-month workflows, reporting deadlines, procurement cycles, and operational handoffs.
Release discipline requires respect for those realities.
A team that pushes a fragile release immediately before a critical operational window is not being agile. It is taking unmanaged business risk.
This is one of the clearest differences between delivery theater and production maturity. Mature teams do not evaluate readiness only at the code level. They also consider when the business can safely absorb uncertainty.
That is why the best release discipline tends to feel less dramatic. It reflects better judgment, not just faster tooling.
Where Release Discipline Helps Most — And Where Teams Misread It
Release discipline creates the most value in systems where change carries real downstream consequences.
That includes:
integration-heavy platforms
pricing or transaction-sensitive systems
customer communications infrastructure
admin and customer portal ecosystems
regulated or compliance-sensitive applications
mature SaaS platforms with accumulated operational complexity
In these environments, the goal is not only to deploy more often. The goal is to make production change more survivable.
Where teams often misread the issue is assuming that more process alone will solve it.
More approvals do not fix weak rollback. More meetings do not fix hidden dependencies. More pipeline stages do not fix unclear ownership. More tooling does not fix poor change scoping.
Release discipline becomes valuable when it reduces uncertainty at the system level.
That is the difference that matters.
The Strategic Question Behind Release Discipline
When production releases keep feeling heavier than they should, the important question is usually not:
How do we make this deploy faster?
It is:
Why does this system require so much coordination just to change safely?
That question points toward architecture boundaries, dependency mapping, environment drift, operational coupling, and platform maturity.
Which means release pain is often an architectural signal.
It tells leadership that the platform may need more than process tightening. It may need a clearer modernization sequence.
That is also why topics like legacy modernization, enterprise integrations, and platform advisory are not separate from release discipline. They are part of the same system-level problem: how to make change less risky in a live environment.
Closing Thought
Release discipline in production systems is not mainly about speed, polish, or DevOps aesthetics.
It is about whether the platform can tolerate change without creating disproportionate operational risk.
That requires smaller changes, credible rollback paths, dependency visibility, environment control, observability, ownership clarity, and better timing judgment.
When those things are in place, releases stop feeling like recurring operational events and start feeling like controlled system behavior.
That shift is more important than most teams realize.
Because in mature platforms, delivery confidence is not built at the moment of deployment.
It is built in the system design and operating discipline that make production change safer in the first place.
If your production releases are becoming harder to coordinate, harder to reverse, or harder to trust, that is usually a sign that the platform needs more than another deployment tool.
Duskbyte's Platform Audit & Roadmap helps CTOs and engineering leaders assess release risk,
architecture friction, dependency complexity,
and modernization priorities so the next phase of platform change is clearer,
more controlled, and easier to defend internally.
We use cookies to enhance your browsing experience, serve personalised ads or content, and analyse our traffic. By clicking "Accept All", you consent to our use of cookies. Cookie Policy