What Should You Modernize First in a Live Production System?
April 7, 2026
8
min read
Modernization Strategy
In a live production system, the first modernization target is rarely the oldest code. It is usually the part of the platform that improves your ability to change the system safely: release controls, rollback paths, observability, brittle integrations, and unstable workflow boundaries. The real question is not what looks most outdated. It is what reduces risk while making the next round of change easier to survive.
The first thing to modernize in a live production system is usually not the thing that looks the oldest.
It is usually the thing that makes future change safer.
That distinction matters more than most teams expect.
When a platform is already serving real customers, carrying real workflows, and supporting day-to-day operations, modernization is no longer a pure technology exercise. It becomes a sequencing decision. The question is not simply what is outdated. The question is what can be improved first to reduce operating risk, increase delivery confidence, and create room for the next phase of change.
In other words, the first modernization target should not be chosen for symbolic value.
It should be chosen for control.
That is why teams dealing with mature platforms often benefit from treating modernization as a phased risk-reduction program rather than a broad rewrite initiative. It is the same reason we often push leaders toward a Platform Audit & Roadmap before they commit to major implementation work: the hard part is rarely agreeing that the system needs help. The hard part is deciding what should move first, what should wait, and what should not be destabilized yet.
The Mistake Most Teams Make
Most teams start in one of three places.
They start with the oldest part of the stack. They start with the most complained-about part of the product. Or they start with the most strategic-sounding initiative.
All three can be reasonable on the surface. All three can also be expensive mistakes.
The oldest module in the platform may be ugly, but still relatively stable. The most complained-about area may create support pain, but not actually drive systemic fragility. The most strategic initiative may sound impressive to leadership, while quietly increasing the blast radius of every release.
This is where live production environments punish shallow prioritization.
A production system is not just a codebase. It is a set of dependencies, release habits, support expectations, hidden workarounds, operating assumptions, and business-critical workflows. Teams that modernize the wrong thing first often discover that the “important” change made the platform harder to reason about before it made it healthier.
That is why the first modernization question should be reframed.
Not: What looks most outdated? But: What most improves our ability to change this system safely?
That is a more useful question for any team trying to modernize without avoidable disruption.
What Usually Deserves to Go First
In most live production systems, the first target is one of the following:
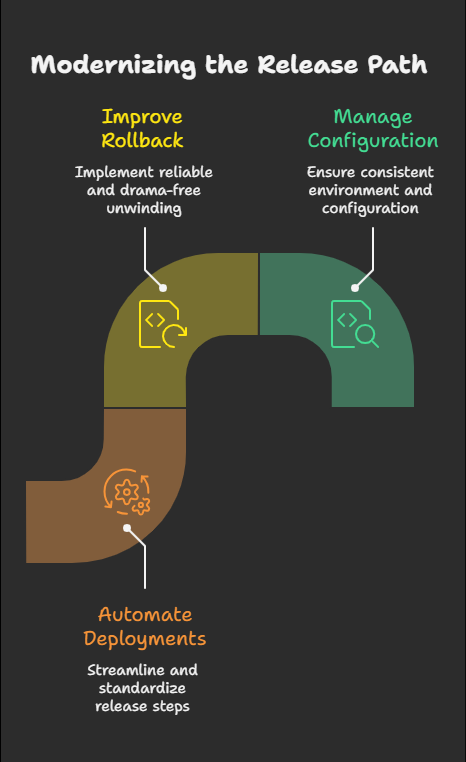
1. The Release and Rollback Path
If releases are fragile, manual, inconsistent, or politically stressful, that is often where modernization should begin.
A platform with weak deployment discipline cannot absorb architectural change well. Even good engineering decisions become risky when the team cannot release predictably, isolate failures quickly, or unwind a bad change without drama.
This is one reason DevOps as risk control is a more useful frame than DevOps as speed theater.
If the system currently depends on:
risky release windows
manual deployment steps
undocumented environment differences
poor rollback mechanisms
brittle configuration management
then modernizing the release path may do more for the platform than rewriting a major subsystem.
Because once delivery becomes more controlled, the next modernization step becomes easier to execute and easier to defend internally.
Anchor line: The first modernization win should often be the ability to change the system with less fear.
2. Observability, Logging, and Failure Visibility
You should be cautious about changing architecture you still cannot see clearly.
A surprising number of mature systems run with poor operational visibility. Teams know they have incidents. They know users hit errors. They know certain workflows feel fragile. But they do not have enough tracing, structured logging, metric coverage, or alert quality to understand where failure actually starts.
That creates a dangerous pattern: teams modernize based on intuition, then discover later that the visible symptom was not the real problem.
Improving observability is not glamorous. It is not usually the headline modernization project. But in live systems it is often one of the most leverage-rich moves available.
A platform that becomes easier to observe becomes easier to modernize.
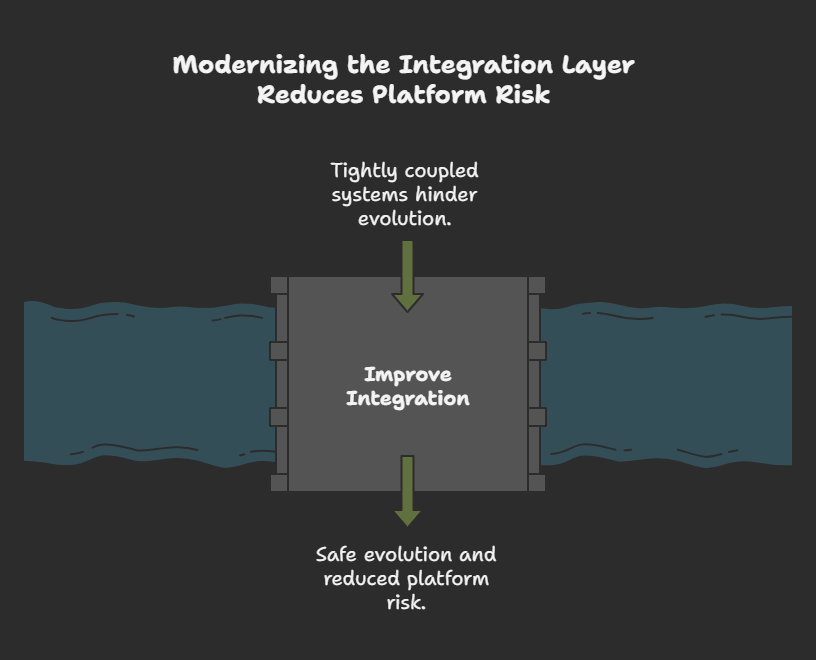
3. The Fragile Integration Layer
In many production systems, the most dangerous part of the platform is not the core business logic. It is the integration surface around it.
This is where real-world complexity tends to accumulate:
undocumented external dependencies
brittle API contracts
batch jobs with hidden timing assumptions
sync processes nobody wants to touch
partner workflows held together by exceptions and retries
internal operational steps compensating for system gaps
If your platform is tightly coupled to external systems, modernization can fail simply because the team underestimates integration fragility.
That is why enterprise integrations often deserve early attention in mature environments. Not because they are more visible to end users, but because they define how safely the rest of the platform can evolve.
In many cases, the right first step is not “replace the integration layer.” It is:
mapping it properly
isolating unstable dependency points
improving contracts
adding resilience and observability
reducing the number of hidden side effects tied to a single change
This is slower to explain than a rewrite story.
It is also much closer to how real platform risk gets reduced.
A calmer way to assess first-move modernization
If your team knows the platform needs to evolve but the correct starting point still feels unclear, that usually means the decision needs more structure, not more urgency.
Our Platform Audit & Roadmap is designed for exactly that stage: identifying where delivery risk, dependency complexity, operational fragility, and sequencing mistakes are most likely to sit before major change begins.
Unclear what should change first?
That usually means the decision needs more structure before delivery pressure forces the wrong sequence.
The Platform Audit & Roadmap
helps leadership teams identify where release risk, dependency fragility, workflow instability, and modernization sequencing mistakes are most likely to sit — before major implementation begins.
Use it to clarify:
The goal is not to prove that the platform can be made modern all at once.
The goal is to create one survivable modernization move that improves the platform without undermining continuity.
What Usually Should Not Go First
Just as important as knowing what should go first is knowing what usually should not.
In a live production system, the wrong first move is often one of these:
A full rewrite
This is the classic modernization trap.
Rewrites promise cleanliness, strategic clarity, and a fresh start. In practice, they often delay learning, expand scope, and separate engineering effort from operating reality.
A live system rarely gives you the luxury of rebuilding in isolation. Business rules, operational habits, support edge cases, and integration assumptions tend to surface late.
That is why phased modernization usually beats rewrite ambition in mature environments.
A cloud migration done for symbolism
Cloud migration may absolutely matter. But if the platform still has fragile releases, poor observability, unstable integrations, or unclear dependency boundaries, moving infrastructure first can simply relocate the same fragility.
Cloud is not the first answer by default.
It is often a later answer once the platform is better prepared for it.
A front-end refresh that leaves system fragility untouched
Sometimes the UI is clearly dated. Sometimes it genuinely hurts the user experience. But in live production systems, a front-end refresh can become a false sense of progress if the real delivery pain sits in workflow logic, data coupling, release discipline, or integration failure.
Visible change is not always structural change.
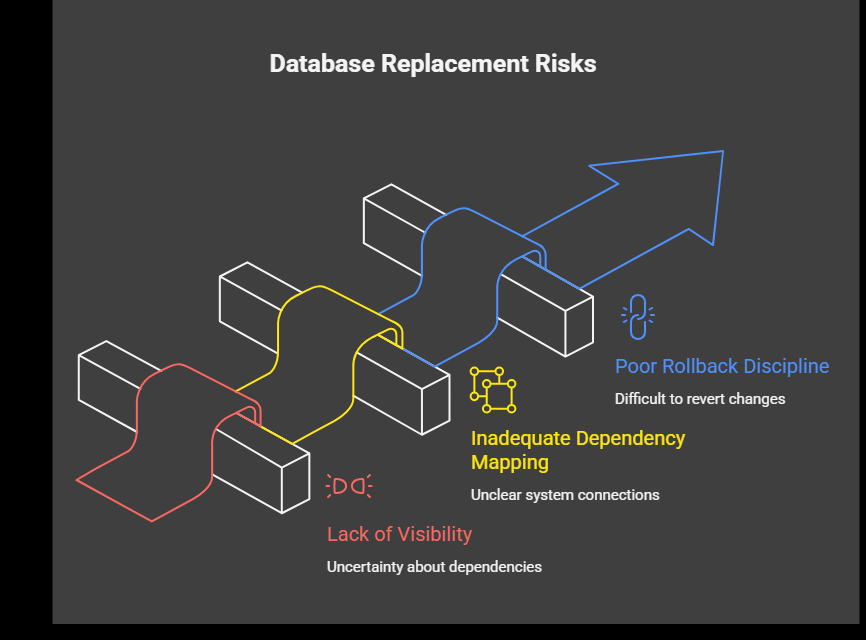
A database replacement without operational clarity
Database modernization can be necessary. It can also be one of the easiest ways to create broad platform instability if the surrounding assumptions are still poorly understood.
If teams have not already improved visibility, dependency mapping, and rollback discipline, replacing a core data layer early can create too much simultaneous uncertainty.
A Better Decision Framework
If you are trying to decide what should be modernized first, these are the questions worth asking:
Which part of the system creates the most change risk?
Not the most annoyance. The most risk.
Which weakness makes every future modernization step harder?
This is often release discipline, visibility, or coupling.
Where does failure create the highest operational cost?
Look beyond technical inconvenience. Focus on support load, business continuity, recovery effort, and stakeholder trust.
Which area changes often enough that improvement compounds quickly?
A high-change workflow is often a better first target than a stable legacy block.
What can be isolated without triggering systemic instability?
The best early modernization step usually has a controlled blast radius.
What gives the team more decision clarity after the change?
A good first move should not only improve the platform. It should improve the next decision.
That last point matters more than it sounds.
The best first modernization step is often the one that makes the rest of the roadmap more obvious.
The Practical Rule
If there is one rule worth keeping, it is this:
Modernize first where the system gains more control, not where the code looks most embarrassing.
That usually means:
safer releases
better rollback paths
stronger visibility
more stable workflow boundaries
reduced integration fragility
clearer system behavior under change
In a live production environment, modernization should earn the right to continue.
It earns that right by making the platform easier to operate, easier to understand, and easier to evolve.
Not by creating the biggest architecture diagram in quarter one.
Closing Thought
The first modernization target in a live production system should not be selected for optics.
It should be selected for survivability.
The most effective teams do not begin with the broadest technical ambition. They begin with the move that reduces risk, improves control, and makes the next step safer than the last one.
That is how mature platforms actually get better.
Not all at once. But in the right order.
Debating whether to start with architecture, cloud migration, integrations, release engineering, or a legacy subsystem?
e
That uncertainty is usually a sign the platform needs clearer sequencing before scope increases.
Duskbyte's Platform Audit & Roadmap
helps CTOs, Heads of Engineering, and platform leaders define:
the safest first modernization move
the main sources of delivery and operating risk
what should happen later instead of now
a phased path that is easier to execute and easier to defend internally
Request a Platform Audit when the platform needs progress, but the order of change still feels risky.
We use cookies to enhance your browsing experience, serve personalised ads or content, and analyse our traffic. By clicking "Accept All", you consent to our use of cookies. Cookie Policy