From Automation to Intelligent Systems: What Changes at Scale
April 8, 2026
8
min read
Modernization Strategy
Automation is often treated as a productivity layer. At scale, that framing stops being useful. Once systems begin interpreting data, recommending actions, or influencing decisions across workflows, the real challenge shifts from task efficiency to control, architecture, and operational safety.
Most teams talk about automation as if it sits neatly inside one box.
A workflow gets triggered. A process step disappears. A report runs automatically. A queue gets routed faster. On paper, that sounds straightforward.
But the real shift happens when automation stops being a set of isolated task reductions and starts becoming part of how the platform interprets inputs, makes recommendations, routes decisions, and shapes operational behavior across the system.
That is the point where the conversation changes.
The question is no longer, “What can we automate?”
It becomes, “What kind of system are we creating, and how much operational responsibility is now being delegated into software?”
That is a very different decision.
For teams already operating live products, this is not just an automation, integrations, and applied AI discussion. It is an enterprise SaaS modernization discussion. It touches architecture, data quality, failure isolation, operational governance, rollback design, and the practical realities of running systems that cannot afford unpredictable behavior.
The mistake most teams make
The common mistake is to treat intelligent behavior as a feature-layer upgrade.
A team automates one or two workflows. Then they add classification, summarization, prediction, scoring, or recommendation logic. Then they start connecting more systems, pushing outputs into operational queues, and reducing human review in the name of speed.
Each step feels incremental.
But the aggregate effect is not incremental.
Once software starts interpreting ambiguous inputs, ranking outcomes, or influencing cross-functional workflows, the platform is no longer just automating tasks. It is participating in judgment.
That is where the risk profile changes.
This is why adding AI or decision logic to a live platform should not be framed as “just another enhancement.” Duskbyte’s own service framing around applied AI for production systems is useful here: the issue is not whether intelligence can be added, but whether it can be added without destabilizing operations, increasing unpredictability, or amplifying weaknesses that already exist in the surrounding system.
What changes when automation becomes a system
1. The surface area expands
Basic automation usually acts on known inputs and known rules.
An intelligent system operates across uncertainty.
It may classify messy data, detect anomalies, generate outputs from incomplete context, route work dynamically, or suggest actions based on probabilistic signals. That means its behavior is shaped not only by business rules, but also by data quality, model boundaries, system context, and workflow design.
At that point, the unit of design is no longer the task.
It is the operating system around the task.
That is why intelligent systems often expose weaknesses in adjacent areas: brittle integrations, unclear ownership, missing auditability, inconsistent schemas, undocumented dependencies, and fragile exception handling. If those conditions already exist, intelligence does not fix them. It tends to accelerate their consequences.
This is especially visible in older environments where legacy SaaS modernization has been postponed and the platform still depends on tightly coupled services, implicit business logic, or undocumented workflows.
2. Data quality becomes a structural issue, not a cleanup task
In ordinary automation, bad data creates friction.
In intelligent systems, bad data creates distorted behavior.
The difference matters.
A deterministic workflow might fail obviously when a field is missing or an API response changes. An intelligent layer may still produce an answer. That answer may look plausible. It may move into an operational workflow. It may influence customer communication, pricing logic, risk scoring, routing priority, or internal decision-making before anyone realizes the underlying context was wrong.
That is why moving from automation to intelligent systems usually requires stronger data contracts, clearer ownership, and better observability than teams initially expect.
the workflow already exists and is reasonably stable
the underlying data is structured enough to support consistent behavior
the cost of a wrong answer is containable
human review can remain in the loop where needed
the system has explicit guardrails, fallback behavior, and traceability
They tend to fail when:
the team is still trying to understand the process itself
the workflow depends heavily on hidden edge cases
ownership is unclear
the platform has poor rollback discipline
outputs are pushed directly into high-consequence operations without sufficient review
That contrast is important.
A document triage assistant, support classification layer, anomaly-detection helper, or internal knowledge workflow may be a good fit.
A pricing engine, financial decision path, compliance-sensitive communication flow, or cross-platform operational control surface usually demands a much higher standard of system design, governance, and release discipline.
That does not mean intelligence has no place in those environments. It means it must be introduced with more restraint.
In governance-heavy operational systems, the safer move is often to use intelligence to support decision-making before allowing it to directly drive execution. That pattern is far more durable than replacing operational judgment too early. It aligns with the same kind of control-oriented thinking visible in Duskbyte’s enterprise pricing platform case study, where the real value came from creating stronger governance, workflow reliability, and operational consistency rather than simply adding more automation.
The failure modes become quieter and more expensive
Traditional software failures are often visible.
A job crashes. A queue backs up. A service times out. A deployment breaks.
Intelligent-system failures are often less obvious.
The output looks acceptable. The recommendation seems reasonable. The summary sounds confident. The routing result feels defensible. Nothing explodes immediately.
But the system may be drifting.
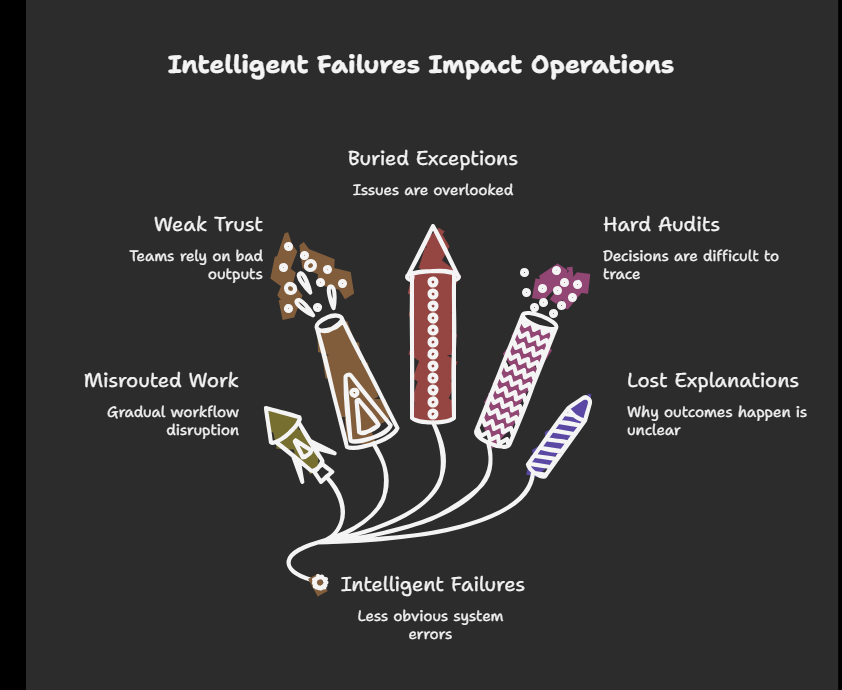
Work may be misrouted gradually. Internal teams may begin trusting weak outputs. Exceptions may get buried. Operational decisions may become harder to audit. Teams may lose the ability to explain why a given outcome happened.
That is the moment when architecture starts to matter more than novelty.
You need event visibility. You need audit trails. You need thresholding. You need fallback paths. You need explicit places where human judgment re-enters the workflow. You need versioning discipline around prompts, rules, model behavior, and downstream integrations. You need clarity on what happens when the system is uncertain.
That is no longer a feature discussion. It is an operating model discussion.
Clarify the system before you scale it
If your platform is moving from simple workflow automation toward recommendation, classification, or model-assisted decision-making, that is usually the point to slow the decision down and assess architecture, data readiness, rollback paths, and ownership.
A Platform Audit helps leadership teams separate low-risk automation from higher-risk intelligent behavior, identify the dependencies that matter, and define a phased path that is easier to defend internally.
At small scale, intelligent behavior can feel like a product capability.
At larger scale, it becomes a governance problem.
Who owns the system’s behavior over time? Who decides what level of error is acceptable? Who can pause or roll back it? Who reviews drift? Who tracks changes in upstream data quality? Who decides when a suggestion becomes an action? Who is accountable when the system behaves plausibly but incorrectly?
Those questions are easy to defer in an experimental phase. They become unavoidable in production.
This is one reason how Duskbyte engages matters as much as implementation. Mature teams usually need decision clarity before they need more automation. They need boundaries, operating rules, and an architecture that supports controlled change.
The infrastructure conversation changes too
A lot of teams assume this evolution is mainly about models and prompts.
It is usually just as much about platform shape.
Once intelligent behavior becomes operationally important, infrastructure decisions start carrying more weight:
where inference or scoring lives
how state is stored and audited
how outputs are versioned
how retries are handled
how errors are surfaced
how downstream systems are protected
how rollback works when behavior changes without a conventional code release
This is where engineering practices and broader cloud migration choices become relevant. A weak platform does not become safer because it is running on newer infrastructure. In many cases, moving quickly into new infrastructure while simultaneously introducing intelligent behavior makes the system harder to reason about, not easier.
That is why the right first move is not always model integration.
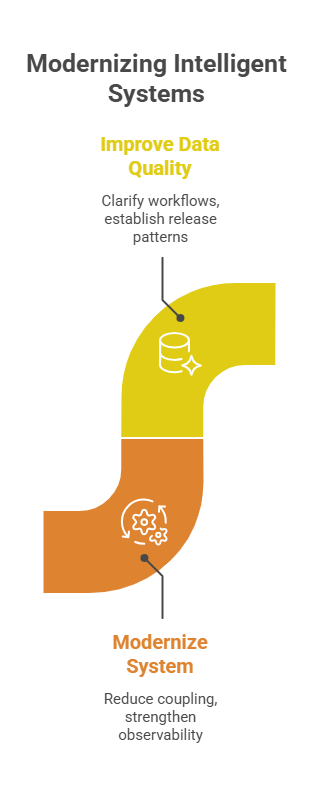
Sometimes the right first move is modernization of the surrounding system: reducing coupling, strengthening observability, clarifying workflows, improving data quality, and establishing safer release patterns.
What serious teams do differently
The strongest teams do not ask whether they should automate or use AI in the abstract.
They ask more disciplined questions:
What decision is being supported? What level of uncertainty is acceptable? What happens when the system is wrong? Can the behavior be explained well enough for the environment it operates in? What is the rollback path? What part of the workflow is stable enough to deserve automation? What part still requires human judgment? Which weaknesses in the platform will be amplified if we add intelligence here?
That way of thinking is slower at the start.
It is also far more scalable.
Because intelligent systems do not become safer through confidence. They become safer through boundaries, operating discipline, and architecture that is designed for live conditions.
The real shift
The shift from automation to intelligent systems is not mainly about sophistication.
It is about responsibility.
Automation removes steps. Intelligent systems influence outcomes.
That means the work is no longer just about efficiency. It is about system design, governance, and operational trust.
For organizations running live, integrated, revenue-sensitive platforms, that distinction matters a great deal.
The teams that handle this transition well are usually the ones that resist the urge to treat intelligence as a shortcut. They treat it as a platform decision. They modernize the surrounding system where needed. They define guardrails before scale. And they introduce capability in phases that the platform can safely absorb.
That is not less ambitious.
It is what serious platform evolution looks like.
Introduce intelligent behavior without increasing platform risk
If your team is under pressure to move beyond basic automation and introduce more intelligent behavior into a live platform, the first question is not which model to use. It is whether the surrounding system is ready for that responsibility.
We use cookies to enhance your browsing experience, serve personalised ads or content, and analyse our traffic. By clicking "Accept All", you consent to our use of cookies. Cookie Policy