How to Evaluate Legacy Systems Without Bias or Assumption
April 9, 2026
8
min read
Modernization Strategy
Legacy systems are often judged too quickly and too emotionally. Some are treated as hopeless because they are old. Others are protected because they still function. Both reactions distort decision-making. A better evaluation starts with evidence: operational risk, dependency density, release behavior, data integrity, and how much of the platform the team actually understands.
Most legacy system discussions go wrong before the evaluation even begins.
The system is already being described as “outdated,” “fragile,” “impossible to scale,” or “too risky to touch.” Sometimes that diagnosis is correct. Often it is only partially correct. In many teams, the language around a legacy platform becomes a substitute for actually understanding it.
That is the real problem.
A mature system should not be evaluated according to how old it looks, how modern the stack sounds, or how frustrated the team feels after a difficult release. It should be evaluated according to what it actually does, how it behaves under change, where the risk sits, and how much of the platform’s business logic is still carrying operational value.
That distinction matters in any serious enterprise SaaS modernization effort. It matters even more when the platform is live, revenue-bearing, integration-heavy, and too important to destabilize for the sake of architectural neatness.
The Mistake Most Teams Make
The most common mistake is not technical. It is interpretive.
Teams inherit a system under pressure. Delivery is slower than it should be. Documentation is incomplete. Release confidence is low. Incidents have created distrust. At that point, it becomes very easy to collapse several different problems into a single conclusion:
“The legacy system is the problem.”
Sometimes the legacy system is the problem. Sometimes the problem is the release process. Sometimes it is hidden dependency coupling. Sometimes it is weak observability. Sometimes it is a data model that nobody wants to revisit. Sometimes the platform is not especially fragile at all; the issue is simply that the team no longer understands its boundaries well enough to change it safely.
These are not the same thing.
That is one reason legacy SaaS modernization should not begin with a rewrite decision, a migration decision, or a tooling decision. It should begin with a structured evaluation.
A Legacy System Is Not One Thing
One of the most unhelpful habits in modernization work is talking about “the legacy system” as though it were a single object.
In reality, most mature platforms are a stack of different conditions living together:
some components are old but stable
some are recent but poorly integrated
some carry critical business rules no one has fully documented
some create operational drag because every change touches too many dependencies
some look ugly in code but are functionally low-risk
some look modern on the surface while hiding dangerous architectural shortcuts underneath
That means evaluation should not ask, “Is this system good or bad?”
It should ask:
Which parts are business-critical?
Which parts are fragile under change?
Which parts are expensive to maintain?
Which parts are misunderstood?
Which parts are constraining future architecture decisions?
Which parts should not be touched yet?
A serious evaluation creates separation where narrative tends to blur everything together.
Separate Evidence From Story
Every legacy platform comes with a story.
“The original architecture was a mess.” “This module is impossible.” “We have to get off this stack.” “Nobody understands this service.” “We cannot scale without replacing it.”
Sometimes these stories are true. But they still need to be tested.
A system evaluation becomes useful when it separates observable evidence from inherited narrative.
Observable evidence includes things like:
incident frequency and blast radius
change failure patterns
rollback frequency
release lead time
dependency density
data correction workload
support burden created by platform behavior
modules that repeatedly block feature delivery
places where security, auditability, or compliance risk is increasing
Inherited narrative includes everything else: frustration, assumptions, team folklore, and second-hand conclusions that may have started as truth but were never revalidated.
Bias does not only show up in executive decision-making. It appears inside engineering evaluations as well.
Rewrite bias
When a system has become painful to work in, a rewrite starts to feel like clarity. But emotional clarity is not the same as operational safety. Duskbyte’s perspective on why most SaaS rewrites fail is relevant here: frustration often makes replacement look simpler than controlled evolution.
Recency bias
Newer components are often assumed to be healthier than older ones. That is not always true. A recently introduced service with poor observability and weak rollback paths may be riskier than an older module that is stable, well-understood, and operationally contained.
Cloud bias
There is a persistent tendency to treat cloud migration as evidence of modernization progress. In reality, moving workloads does not resolve weak boundaries, bad coupling, brittle data flows, or release instability. A platform may still need SaaS cloud migration, but that decision should come after the system is understood, not before.
Architecture purity bias
Teams sometimes overvalue conceptual elegance and undervalue operational survivability. The cleanest target architecture on a whiteboard is not automatically the most responsible next move in production.
Trauma bias
One severe incident can permanently distort how a platform is judged. That incident may reveal a real systemic weakness. It may also cause teams to overgeneralize from one failure mode and mis-prioritize the rest of the system.
What A Useful Evaluation Actually Looks At
A legacy system should be evaluated across several dimensions at the same time.
1. Operational criticality
What business process depends on this system continuing to behave correctly?
A module serving a cosmetic internal workflow should not be assessed the same way as a subsystem responsible for billing, pricing, customer communications, entitlements, or compliance-sensitive data handling.
2. Change risk
Where does change repeatedly create regressions, rework, or release anxiety?
This is often more useful than asking which code looks oldest. Age matters less than the combination of tight coupling, weak testing confidence, undocumented behavior, and lack of rollback safety.
3. Dependency density
Which parts of the platform sit at the intersection of too many services, integrations, jobs, vendors, or data flows?
High dependency density is often where modernization risk becomes operationally real. It is also where the evaluation should be especially careful.
4. Data integrity exposure
Where would a “simple improvement” create downstream data inconsistency, reporting distortion, customer-facing errors, or audit problems?
This is one reason system evaluation should never be reduced to code quality alone.
5. Release discipline
How do changes move into production today?
If the platform lacks reliable test environments, rollback discipline, deployment visibility, or release ownership, then the problem may not be the system in isolation. It may be the delivery mechanism around it. That is why Duskbyte’s how we work and modernization model places so much emphasis on sequencing, validation, and controlled change rather than speed theater.
6. Team comprehension
What does the current team actually understand?
This is one of the least discussed but most important factors. A system that is partially undocumented but still understood by experienced operators is in a different condition from a system that nobody can explain with confidence.
7. Economic drag
Where is the platform creating meaningful cost through delay, workarounds, support load, incident recovery, or feature deferral?
A useful evaluation connects technical conditions to business friction. Without that step, every modernization argument stays abstract.
Need a Clearer View Before You Modernize?
If your team is trying to decide whether a platform is truly fragile or simply poorly understood, a structured Platform Audit & Roadmap helps separate evidence from assumption. It gives technical leaders a practical way to assess architecture risk, delivery constraints, dependency concentration, and modernization priorities before larger commitments are made.
The Most Important Distinction: Old Does Not Mean Wrong
Some legacy systems are genuinely dangerous. Others are just inconvenient. Others are carrying more business logic than anyone wants to admit.
That distinction matters because “modernization” can destroy value when it treats embedded operational knowledge as accidental complexity. Mature systems often contain years of exception handling, domain rules, customer-specific behavior, workaround logic, and integration patterns that were never documented cleanly but still matter.
A biased evaluation sees only technical debt. A responsible evaluation asks what knowledge is encoded in the platform, what should be extracted, what should be preserved, and what can be retired safely.
That is especially true in the kinds of environments reflected across Duskbyte’s industries work, where high-volume workflows, admin tooling, compliance pressures, and integration sprawl tend to accumulate over time rather than appear all at once.
What A Good Evaluation Produces
A good legacy system evaluation does not end with a dramatic conclusion.
It usually produces something more useful:
a clearer map of business-critical dependencies
a better understanding of where change risk is concentrated
a more honest distinction between fragility and inconvenience
a shortlist of areas that deserve immediate attention
a set of areas that should be left alone for now
a more credible basis for modernization sequencing
In other words, it creates decision clarity.
That is the point.
The goal is not to prove that the system is bad. The goal is not to defend the status quo. The goal is to make better decisions than the organization could make while operating on assumption, frustration, or inherited narrative.
Questions Worth Asking Before You Touch Anything
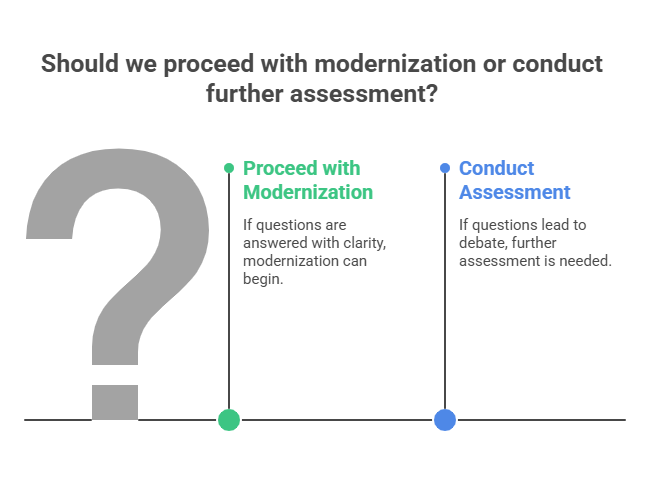
Before committing to a major modernization program, technical leaders should be able to answer questions like these:
Which parts of the system create the highest operational risk today?
Which parts are slowing delivery most severely?
Which dependencies make safe change difficult?
Which data flows are least tolerant of disruption?
Which assumptions about the system have never actually been tested?
Which improvements require architectural change, and which only require better delivery discipline?
What should happen now, what should happen later, and what is firmly not yet?
If those questions still produce debate instead of clarity, the right next step is usually assessment, not acceleration.
Closing Thought
Legacy systems should be evaluated with skepticism, but not with prejudice.
They deserve neither blind defense nor automatic condemnation.
A mature platform is often a mix of resilient foundations, accumulated compromises, undocumented logic, and uneven risk. Good judgment begins when the team stops trying to label the whole system in one sentence and starts identifying what is actually true.
That is how modernization becomes safer. That is how priorities become more defensible. And that is how teams avoid making expensive platform decisions based on bias disguised as certainty.
Request a Platform Audit & Roadmap
If you are evaluating a live platform and the internal conversation is already drifting toward assumptions, rewrite pressure, or architecture theater, Duskbyte’s Platform Audit & Roadmap provides a structured way to assess architecture, operational risk, delivery constraints, dependency density, and modernization sequencing. The result is a more defensible view of what should change now, what should wait, and what should not be touched yet.
We use cookies to enhance your browsing experience, serve personalised ads or content, and analyse our traffic. By clicking "Accept All", you consent to our use of cookies. Cookie Policy