Enterprise systems rarely break because two platforms cannot technically connect.
They break because the connection becomes the place where too much responsibility accumulates.
Business rules leak into adapters. External payloads start shaping internal models. Retry logic becomes workflow logic. Vendor assumptions spread into production behavior. Over time, what began as a simple integration becomes a fragile dependency that quietly controls far more of the platform than anyone intended.
A healthy integration boundary does not merely move data from one place to another.
It performs a more important function: it contains volatility.
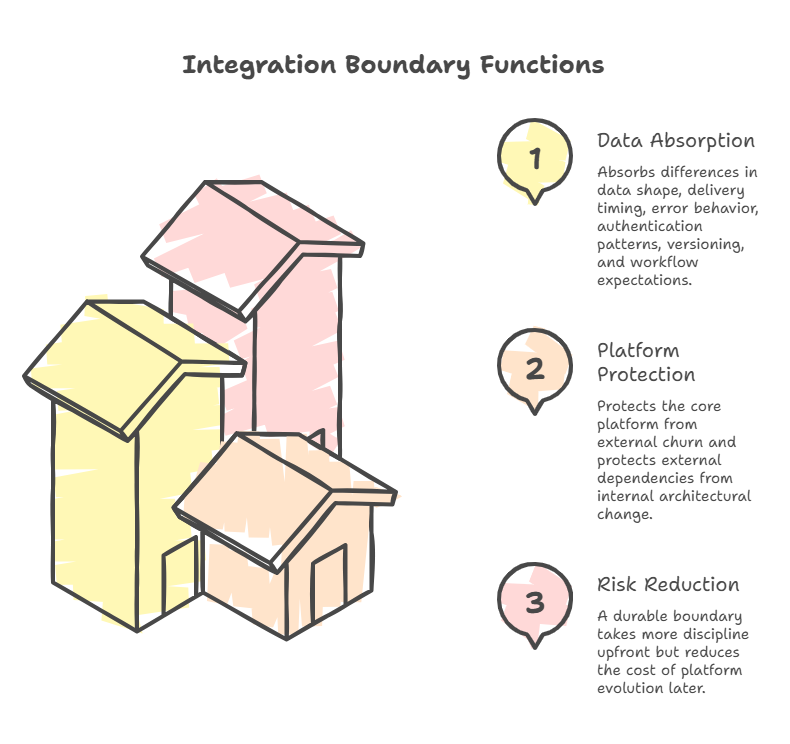
That means the boundary should absorb differences in data shape, delivery timing, error behavior, authentication patterns, versioning, and workflow expectations without forcing the rest of the platform to constantly adapt.
A strong integration boundary protects the core platform from external churn and protects external dependencies from internal architectural change.
That is a very different design objective from “make the API work.”
In live systems, the difference matters. A thin connection may be quick to build, but it often turns normal change into operational risk. A durable boundary takes more discipline upfront, but it reduces the cost of platform evolution later.
Why Integration Layers Become Fragile
Most fragile integration layers are not badly intended. They are usually the result of local decisions made under delivery pressure.
A team needs to ship quickly, so they map a vendor payload directly into internal logic. Another team adds a special case for one partner. A third team handles exceptions in a scheduled sync because changing the original workflow feels too risky. Soon the platform is no longer integrating through a controlled boundary. It is negotiating with accumulated history.
This is especially common in environments with:
multiple third-party systems
aging internal platforms
workflow-heavy operations
partner-specific rules
partial cloud migration
team handoffs over several years
These are exactly the kinds of environments where Duskbyte’s risk-first approach and how-we-work model become relevant. The challenge is rarely connectivity alone. It is managing dependency behavior under real production constraints.
What Durable Boundaries Usually Include
Designing an integration boundary that survives change usually requires a few deliberate choices.
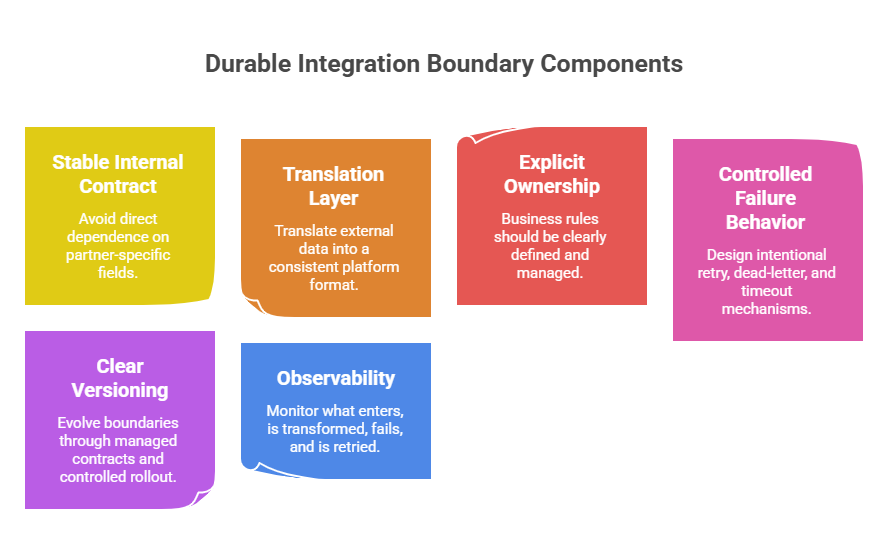
1. A Stable Internal Contract
The rest of the platform should not depend directly on partner-specific fields, naming conventions, or event shapes. External systems change for their own reasons. Your core platform should not be forced to rewire itself every time they do.
2. A Translation Layer, Not a Mirror
A boundary should translate external data into a form the platform can reason about consistently. Mirroring third-party schemas too closely often creates long-term coupling disguised as convenience.
3. Explicit Ownership of Business Rules
Business rules should not be hidden inside webhook handlers, ETL jobs, or ad hoc transformation scripts. When integration code becomes the place where core business decisions live, the boundary becomes both fragile and hard to govern.
4. Controlled Failure Behavior
Retries, dead-letter handling, idempotency, replay, and timeout behavior should be designed intentionally. Otherwise, minor upstream instability can become duplicate actions, silent data drift, or broken downstream workflows.
5. Clear Versioning and Change Discipline
Durable boundaries are not static. They evolve. But they evolve through managed contracts, controlled rollout, and clear ownership rather than informal patching.
6. Observability at the Boundary
If teams cannot see what entered, what was transformed, what failed, and what was retried, they are not managing an integration boundary. They are guessing about one.
Technical Deep Dives
Designing Integration Boundaries That Survive Change
April 15, 2026
8
min read
Platform Stability
Integration failures rarely begin with a broken API. They usually begin with a boundary that was never designed to contain change in the first place. In live enterprise systems, durable integration architecture is less about connectivity and more about control, translation, and operational resilience.
Enterprise systems rarely break because two platforms cannot technically connect.
They break because the connection becomes the place where too much responsibility accumulates.
Business rules leak into adapters. External payloads start shaping internal models. Retry logic becomes workflow logic. Vendor assumptions spread into production behavior. Over time, what began as a simple integration becomes a fragile dependency that quietly controls far more of the platform than anyone intended.
A healthy integration boundary does not merely move data from one place to another.
It performs a more important function: it contains volatility.
That means the boundary should absorb differences in data shape, delivery timing, error behavior, authentication patterns, versioning, and workflow expectations without forcing the rest of the platform to constantly adapt.
A strong integration boundary protects the core platform from external churn and protects external dependencies from internal architectural change.
That is a very different design objective from “make the API work.”
In live systems, the difference matters. A thin connection may be quick to build, but it often turns normal change into operational risk. A durable boundary takes more discipline upfront, but it reduces the cost of platform evolution later.
Why Integration Layers Become Fragile
Most fragile integration layers are not badly intended. They are usually the result of local decisions made under delivery pressure.
A team needs to ship quickly, so they map a vendor payload directly into internal logic. Another team adds a special case for one partner. A third team handles exceptions in a scheduled sync because changing the original workflow feels too risky. Soon the platform is no longer integrating through a controlled boundary. It is negotiating with accumulated history.
This is especially common in environments with:
multiple third-party systems
aging internal platforms
workflow-heavy operations
partner-specific rules
partial cloud migration
team handoffs over several years
These are exactly the kinds of environments where Duskbyte’s risk-first approach and how-we-work model become relevant. The challenge is rarely connectivity alone. It is managing dependency behavior under real production constraints.
What Durable Boundaries Usually Include
Designing an integration boundary that survives change usually requires a few deliberate choices.
1. A Stable Internal Contract
The rest of the platform should not depend directly on partner-specific fields, naming conventions, or event shapes. External systems change for their own reasons. Your core platform should not be forced to rewire itself every time they do.
2. A Translation Layer, Not a Mirror
A boundary should translate external data into a form the platform can reason about consistently. Mirroring third-party schemas too closely often creates long-term coupling disguised as convenience.
3. Explicit Ownership of Business Rules
Business rules should not be hidden inside webhook handlers, ETL jobs, or ad hoc transformation scripts. When integration code becomes the place where core business decisions live, the boundary becomes both fragile and hard to govern.
4. Controlled Failure Behavior
Retries, dead-letter handling, idempotency, replay, and timeout behavior should be designed intentionally. Otherwise, minor upstream instability can become duplicate actions, silent data drift, or broken downstream workflows.
5. Clear Versioning and Change Discipline
Durable boundaries are not static. They evolve. But they evolve through managed contracts, controlled rollout, and clear ownership rather than informal patching.
6. Observability at the Boundary
If teams cannot see what entered, what was transformed, what failed, and what was retried, they are not managing an integration boundary. They are guessing about one.
Need clearer integration architecture before changing live systems?
Duskbyte’s SaaS Modernization & Cloud Readiness Audit helps technical leaders identify fragile integration points, hidden coupling, sequencing risk, and the safest path for modernization.
Start with a structured assessment, not a rushed rebuild.
A Boundary Should Reduce Blast Radius, Not Expand It
One useful test is simple:
When this integration changes, how much of the platform has to care?
If the answer is “several services, multiple workflows, downstream analytics, and manual support processes,” the boundary is probably too porous.
Well-designed boundaries reduce blast radius. They keep change local. They make failure visible. They separate transport concerns from business concerns. They create room for the platform to evolve without renegotiating every external dependency each time.
This is one reason integration architecture is so central to SaaS cloud migration and broader modernization work. Moving workloads, changing hosting models, or introducing new event infrastructure does not solve a boundary problem by itself. It may simply relocate the same fragility into a different operating environment.
Where Teams Usually Get Sequencing Wrong
A common mistake is modernizing the integration technology before modernizing the integration boundary.
The team introduces a message bus, replaces cron-based sync with event-driven flows, adopts a new integration platform, or adds workflow automation. On paper, the architecture looks more modern. In practice, the underlying ambiguity remains:
internal ownership is still unclear
external contracts still leak inward
workflow rules still live in edge code
failure handling is still inconsistent
partner-specific logic is still scattered
The technology changes. The operational risk stays.
That is why many integration problems are really sequencing problems. Before choosing new infrastructure, teams often need to decide what the boundary is actually supposed to protect, what logic belongs inside it, and what should never cross it in the first place.
Consider a platform that connects pricing logic, supplier data, customer portals, and downstream fulfillment systems.
At first, the integration work looks straightforward. Pull supplier data in. Normalize it. Push approved changes outward. Notify downstream systems.
But over time, reality intervenes.
One supplier sends incomplete records. Another changes identifiers. One customer-facing workflow needs same-day visibility while another should only update after approval. Support teams need exception handling. Finance needs traceability. Operations need to know whether a failed sync means “retry later” or “do not proceed.”
Now the integration boundary is no longer a connector. It is a control surface.
That is the point at which boundary design becomes strategic. If the platform treats that integration layer as a place to absorb inconsistency, enforce translation, preserve auditability, and isolate downstream effects, it becomes more resilient. If it treats the layer as a pass-through, the rest of the platform inherits the instability.
Questions Worth Asking Before You Redesign an Integration Layer
Before changing an integration boundary, leadership teams usually benefit from asking a narrower set of questions than they first expect.
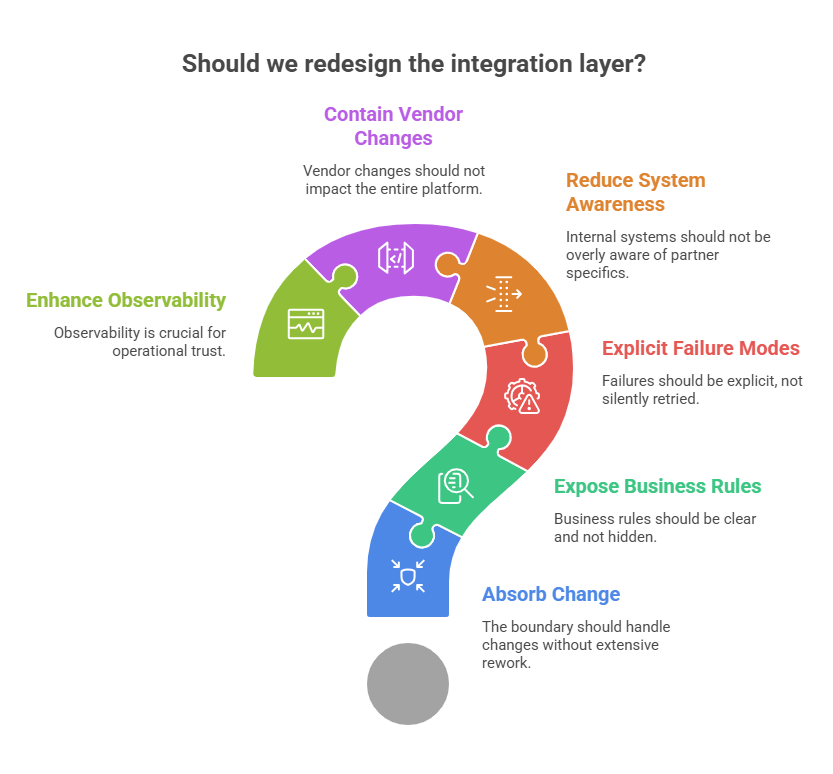
What kinds of change should this boundary absorb without forcing platform-wide rework?
Which business rules are currently hiding inside adapters, scripts, or sync logic?
What failure modes need to be explicit rather than silently retried?
Which internal systems are too aware of partner-specific assumptions today?
If a vendor changes schema, timing, or authentication, where should that impact stop?
What would observability need to show for this boundary to be operationally trustworthy?
Those questions often matter more than whether the next iteration uses webhooks, queues, iPaaS tooling, or custom services. The implementation matters, but the containment model matters first.
The Best Boundaries Are Designed for Organizational Change Too
Technical change is only one kind of change.
In mature platforms, integrations also need to survive:
team turnover
vendor replacement
product expansion
compliance demands
new reporting requirements
shifts in operational ownership
A boundary that only works when the same engineers remain in place is not a resilient boundary. A boundary that cannot be reasoned about by support, operations, architecture, and engineering together is not reducing risk. It is concentrating it.
This is why integration architecture should be treated as part of platform governance, not just implementation detail. It shapes how safely the platform can evolve over time.
Conclusion
Designing integration boundaries that survive change is not about building heavier interfaces or more elaborate middleware.
It is about making sure the platform has controlled places where change can be absorbed, translated, observed, and governed.
In stable systems, integration boundaries are not convenience wrappers. They are protection layers.
They preserve clarity between systems. They reduce the spread of external volatility. They stop local exceptions from becoming platform-wide behavior. And they make modernization easier to sequence because the team knows where change belongs and where it does not.
That is what durable integration design really buys: not just connectivity, but control.
Planning to modernize an integration-heavy platform?
Duskbyte works with CTOs and engineering leaders who need to improve live systems without creating new operational fragility. Our Platform Audit and modernization assessment helps teams identify where boundaries are weak, where coupling is hidden, and how to modernize with better sequencing and lower risk.
We use cookies to enhance your browsing experience, serve personalised ads or content, and analyse our traffic. By clicking "Accept All", you consent to our use of cookies. Cookie Policy