Modernization is usually framed as the responsible move.
A platform has grown harder to change. Releases feel tense. Teams are working around old constraints. Cloud pressure is rising. Integration complexity is accumulating. Leadership can see that something needs to improve.
That part is often true.
What gets missed is this: modernization does not reduce risk automatically. It only reduces risk when the team is clear about what problem is actually being solved, what constraints are still active, and what sequence of change the platform can realistically absorb.
Without that clarity, modernization becomes another source of fragility.
Teams start replacing parts of the system before they understand why those parts became difficult in the first place. They move workloads before operational dependencies are visible. They introduce automation before the process underneath it is stable. They reorganize architecture before ownership, failure modes, and rollback boundaries are clear.
The result is familiar. The old system is still difficult, but now the new path is difficult too.
The most dangerous modernization programs are not the ones doing nothing. They are the ones changing important systems without a clear model of risk.
The mistake is not action. It is unclear action.
Most teams do not lack effort.
They lack decision clarity.
In practice, that usually means one of four things.
The first is that the technical move has been chosen before the platform problem has been defined. The team decides to migrate, re-platform, split services, or replace a subsystem before reaching agreement on what is actually causing delivery friction, instability, cost, or operational drag.
The second is that visible progress gets mistaken for structural progress. A cleaner interface, a new infrastructure layer, or a fresh service boundary can look like modernization, even while the real operational burden remains where it was.
The third is that the program becomes too broad too early. Once a modernization initiative gets budget, sponsorship, and momentum, it can start absorbing unrelated change. That makes the work look strategic while making the platform harder to reason about.
The fourth is that nobody has defined what “safer” should look like. Teams say they want modernization to reduce risk, but do not define how that reduction will be measured. Fewer release incidents? Better rollback confidence? Clearer ownership? Lower integration fragility? Better delivery predictability? Without that definition, the program can stay active while confidence declines.
Why teams create new risk while fixing old systems
Old systems rarely fail for one reason alone.
They become fragile through accumulation. Hidden dependencies. Manual workarounds. Deployment fear. Mixed ownership. Inconsistent contracts between services. Data assumptions nobody wants to touch. Exception paths that only exist because the business needed them at the time.
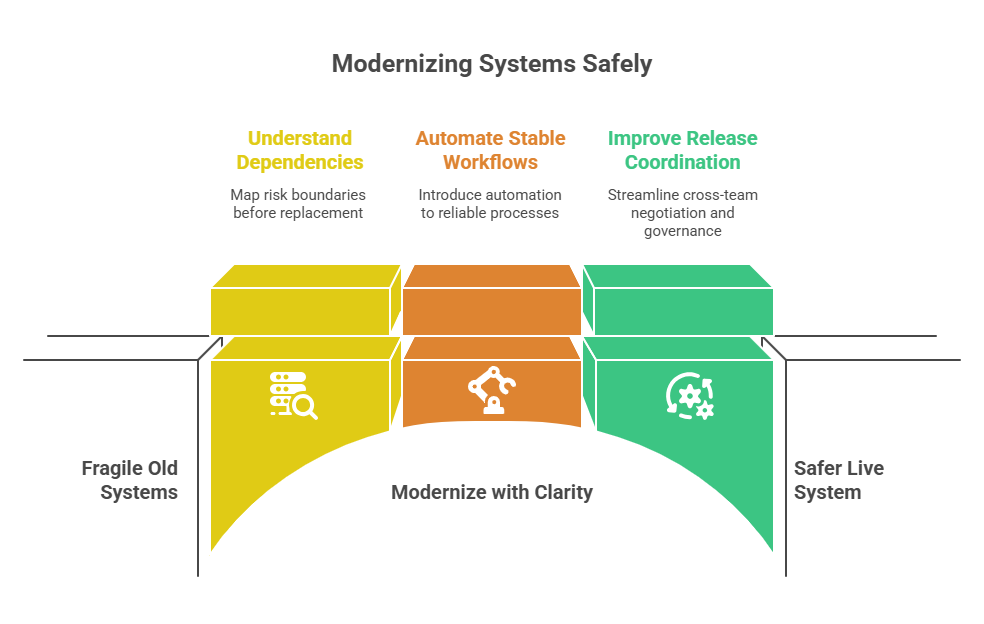
When a team modernizes without clarity, it often changes one layer while leaving the real dependency pattern untouched.
A few common examples show up repeatedly.
1. Infrastructure changes before dependency truth is understood
Moving infrastructure can look like progress because it is visible and sponsor-friendly. But hosting changes do not automatically fix service coupling, brittle data flows, or operational ambiguity.
That is why enterprise SaaS modernization should not begin with a platform move alone. If the system still depends on undocumented behavior, weak release discipline, or fragile integration contracts, a new environment can simply make those problems more expensive.
2. Legacy replacement begins before risk boundaries are mapped
Many teams know they need legacy SaaS modernization. The mistake is assuming that old code is the risk, when the real risk may be business logic concentration, implicit workflow sequencing, or operational knowledge locked inside a small set of people.
Replacing code without clarifying those dependencies often creates a dangerous overlap period: the old system is still carrying real business load, while the new one is incomplete, partially understood, and structurally different in ways the business has not fully absorbed.
3. Automation gets added to unstable workflows
Automation can reduce friction. It can also multiply fragility.
When teams introduce automation, integrations, and applied AI into workflows that already rely on manual correction, undocumented exceptions, or inconsistent upstream data, they do not remove chaos. They accelerate it.
The system becomes faster at producing the wrong result.
4. Architecture gets cleaner while operations get harder
This is one of the more subtle failure patterns.
A technical architecture review may conclude that a cleaner separation of concerns is needed. That can be correct. But if the transition path introduces more release coordination, more cross-team negotiation, or more incident ambiguity before governance improves, then the platform may become harder to operate even as the diagram becomes more elegant.
Modernization is not judged only by how clean the future state looks. It is judged by whether the live system becomes safer to change.
What clarity actually means in modernization work
Clarity is not a vague desire for better planning.
It is the discipline of making certain things explicit before high-impact change begins.
That includes questions like:
What problem is creating the most operational drag right now?
Which dependencies are still poorly understood?
What part of the system carries the highest change risk?
Where does release confidence break down?
Which workflows depend on legacy behavior the business still needs?
What can be isolated safely, and what cannot?
What must become more predictable before the next phase begins?
Those questions are more useful than asking which stack is newer, which architecture is more fashionable, or which migration path looks cleaner on a roadmap slide.
For teams under pressure, how Duskbyte works is built around this exact point: clarity before acceleration.
Modernization Decisions
Modernization Without Clarity: How Teams Create New Risk While Fixing Old Systems
April 14, 2026
8
min read
Modernization Strategy
Modernization is supposed to reduce fragility. But without decision clarity, it often creates new instability while teams are still trying to remove the old kind. In live production systems, unclear priorities, weak dependency mapping, and premature technical moves can turn a sensible modernization effort into a new source of operational risk.
Modernization is usually framed as the responsible move.
A platform has grown harder to change. Releases feel tense. Teams are working around old constraints. Cloud pressure is rising. Integration complexity is accumulating. Leadership can see that something needs to improve.
That part is often true.
What gets missed is this: modernization does not reduce risk automatically. It only reduces risk when the team is clear about what problem is actually being solved, what constraints are still active, and what sequence of change the platform can realistically absorb.
Without that clarity, modernization becomes another source of fragility.
Teams start replacing parts of the system before they understand why those parts became difficult in the first place. They move workloads before operational dependencies are visible. They introduce automation before the process underneath it is stable. They reorganize architecture before ownership, failure modes, and rollback boundaries are clear.
The result is familiar. The old system is still difficult, but now the new path is difficult too.
The most dangerous modernization programs are not the ones doing nothing. They are the ones changing important systems without a clear model of risk.
The mistake is not action. It is unclear action.
Most teams do not lack effort.
They lack decision clarity.
In practice, that usually means one of four things.
The first is that the technical move has been chosen before the platform problem has been defined. The team decides to migrate, re-platform, split services, or replace a subsystem before reaching agreement on what is actually causing delivery friction, instability, cost, or operational drag.
The second is that visible progress gets mistaken for structural progress. A cleaner interface, a new infrastructure layer, or a fresh service boundary can look like modernization, even while the real operational burden remains where it was.
The third is that the program becomes too broad too early. Once a modernization initiative gets budget, sponsorship, and momentum, it can start absorbing unrelated change. That makes the work look strategic while making the platform harder to reason about.
The fourth is that nobody has defined what “safer” should look like. Teams say they want modernization to reduce risk, but do not define how that reduction will be measured. Fewer release incidents? Better rollback confidence? Clearer ownership? Lower integration fragility? Better delivery predictability? Without that definition, the program can stay active while confidence declines.
Why teams create new risk while fixing old systems
Old systems rarely fail for one reason alone.
They become fragile through accumulation. Hidden dependencies. Manual workarounds. Deployment fear. Mixed ownership. Inconsistent contracts between services. Data assumptions nobody wants to touch. Exception paths that only exist because the business needed them at the time.
When a team modernizes without clarity, it often changes one layer while leaving the real dependency pattern untouched.
A few common examples show up repeatedly.
1. Infrastructure changes before dependency truth is understood
Moving infrastructure can look like progress because it is visible and sponsor-friendly. But hosting changes do not automatically fix service coupling, brittle data flows, or operational ambiguity.
That is why enterprise SaaS modernization should not begin with a platform move alone. If the system still depends on undocumented behavior, weak release discipline, or fragile integration contracts, a new environment can simply make those problems more expensive.
2. Legacy replacement begins before risk boundaries are mapped
Many teams know they need legacy SaaS modernization. The mistake is assuming that old code is the risk, when the real risk may be business logic concentration, implicit workflow sequencing, or operational knowledge locked inside a small set of people.
Replacing code without clarifying those dependencies often creates a dangerous overlap period: the old system is still carrying real business load, while the new one is incomplete, partially understood, and structurally different in ways the business has not fully absorbed.
3. Automation gets added to unstable workflows
Automation can reduce friction. It can also multiply fragility.
When teams introduce automation, integrations, and applied AI into workflows that already rely on manual correction, undocumented exceptions, or inconsistent upstream data, they do not remove chaos. They accelerate it.
The system becomes faster at producing the wrong result.
4. Architecture gets cleaner while operations get harder
This is one of the more subtle failure patterns.
A technical architecture review may conclude that a cleaner separation of concerns is needed. That can be correct. But if the transition path introduces more release coordination, more cross-team negotiation, or more incident ambiguity before governance improves, then the platform may become harder to operate even as the diagram becomes more elegant.
Modernization is not judged only by how clean the future state looks. It is judged by whether the live system becomes safer to change.
What clarity actually means in modernization work
Clarity is not a vague desire for better planning.
It is the discipline of making certain things explicit before high-impact change begins.
That includes questions like:
What problem is creating the most operational drag right now?
Which dependencies are still poorly understood?
What part of the system carries the highest change risk?
Where does release confidence break down?
Which workflows depend on legacy behavior the business still needs?
What can be isolated safely, and what cannot?
What must become more predictable before the next phase begins?
Those questions are more useful than asking which stack is newer, which architecture is more fashionable, or which migration path looks cleaner on a roadmap slide.
For teams under pressure, how Duskbyte works is built around this exact point: clarity before acceleration.
Need Help Clarifying What Should Change First?
A modernization program becomes far safer when the team can separate structural priorities from reactive activity.
A Platform Audit helps leadership teams assess architecture risk, dependency patterns, integration complexity, and sequencing constraints before they commit to expensive platform change.
Better modernization usually starts with a narrower ambition and a stronger decision model.
Not “transform the platform.”
Not “move everything important this year.”
Not “modernize the stack.”
Instead:
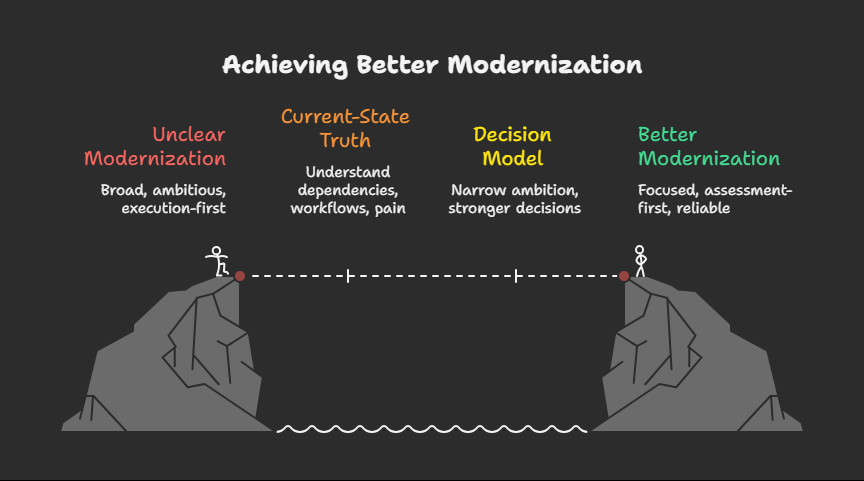
Start with current-state truth
Before designing a target state, the team needs a reliable understanding of the present state. That means actual dependency mapping, real workflow observation, operational pain analysis, release-path review, and clarity on where failures are absorbed today.
Some debt is expensive but stable. Some is messy but isolated. Some is ugly but well understood. The real priority is usually the combination of fragility and operational significance.
The strongest modernization decisions focus on the places where instability, uncertainty, and business impact overlap.
Sequence by constraint, not by novelty
A mature platform should not be modernized in the order that sounds most exciting.
It should be modernized in the order that reduces downstream risk.
That often means stabilizing release paths before expanding architecture, clarifying data and integration boundaries before pushing automation deeper, and reducing operational ambiguity before introducing new platform layers.
This is also why why most SaaS rewrites fail remains such an important lesson. Big technical moves often promise clarity later while increasing uncertainty now.
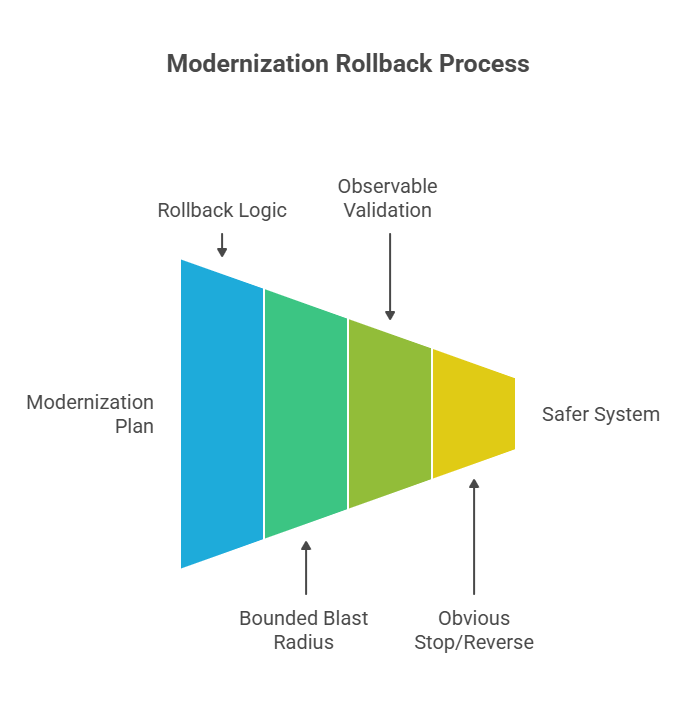
Treat rollback and containment as design requirements
A modernization plan without clear rollback logic is not mature enough for a live system.
Every phase should have bounded blast radius, observable validation points, and an obvious way to stop or reverse change before a local issue becomes a broader operational event.
That is not caution theatre. It is platform responsibility.
Keep ownership visible throughout the transition
Many modernization programs fail in the middle, not at the beginning.
The reason is often ownership drift. Teams know who owns the current system and who wants the future state, but the transition phase becomes politically and operationally unclear.
Good modernization keeps ownership, validation responsibility, and go-live accountability explicit at each step.
Why clarity is often mistaken for delay
There is a persistent belief that slowing down to gain clarity is a form of hesitation.
In enterprise systems, the opposite is often true.
Clarity is what stops a modernization effort from spending six months improving the wrong layer.
Clarity is what prevents architecture work from outrunning operational reality.
Clarity is what helps leaders explain why one problem should be addressed now, another later, and a third not yet.
That is not delay.
That is control.
And in live systems, control is usually more valuable than speed theatre.
The real goal is not change. It is safer change.
Teams rarely get credit for modernization effort alone.
They get judged on whether the platform becomes more stable, more understandable, and easier to evolve without incident.
That is the standard that matters.
A modernization program should reduce ambiguity, not add another layer of it. It should improve delivery confidence, not simply produce more architecture artifacts. It should make the next decision easier, not harder to defend.
Without clarity, teams create new risk while trying to remove the old kind.
With clarity, modernization becomes what it should have been from the beginning: a controlled way to improve a live system without making it less survivable in the process.
Clarify the Next Modernization Decision Before Expanding the Program
If your platform is under pressure to modernize but the work still feels broad, politically difficult, or operationally unclear, that usually means more activity is not the answer yet.
A Platform Audit gives leadership a clearer view of architecture constraints, integration risk, cloud-readiness factors, and sequencing priorities so the next phase of change is easier to defend and safer to execute. You can also review our approach, how we work, or learn more about Duskbyte.
We use cookies to enhance your browsing experience, serve personalised ads or content, and analyse our traffic. By clicking "Accept All", you consent to our use of cookies. Cookie Policy