What Real Cloud Incidents Reveal About System Design
April 7, 2026
8
min read
Cloud Risk
Cloud outages are often discussed as vendor reliability problems. In practice, the most useful lesson is usually closer to home. Real incidents reveal how hidden dependencies, control-plane coupling, retry behavior, and weak blast-radius design can turn a localized problem into a platform-wide event.
Cloud incidents are easy to misread.
Teams often treat them as proof that a provider failed, a region was unlucky, or availability is ultimately someone else’s problem. That is usually the least useful interpretation.
The better reading is this: real incidents reveal what the architecture actually depends on.
Not the architecture diagram in the planning deck. Not the resilience story in the migration proposal. The real one.
When production systems fail under pressure, they expose which subsystems are truly foundational, which recovery assumptions were incomplete, and which dependencies were never treated as part of the critical path. That is why cloud incidents matter so much to platform leaders. They do not just tell you what broke at AWS, Google Cloud, or Cloudflare. They show what kinds of design assumptions break everywhere.
The common mistake is to treat resilience as a hosting attribute.
If the provider is strong, the system is resilient. If the region has multiple zones, the design is resilient. If backups, auto-scaling, and failover exist somewhere in the stack, the platform is resilient.
Real incidents keep showing the opposite.
Resilience is not created by cloud usage alone. It is created by dependency design, control boundaries, recovery paths, and failure containment. The cloud changes the tools available to you. It does not remove the need for system judgment.
That matters because mature platforms rarely fail at the obvious layer. They fail in the layer beneath the one everyone was watching.
What the incidents actually show
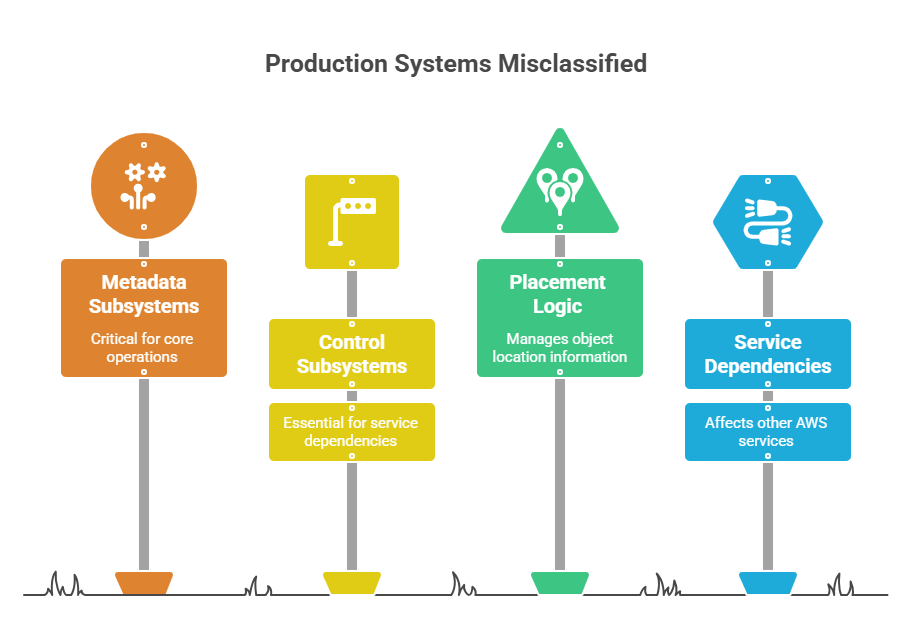
1. Metadata and control subsystems are production systems
One of the clearest lessons came from AWS’s February 2017 S3 disruption in us-east-1. According to AWS’s own summary, an authorized maintenance command removed a larger set of servers than intended from S3 subsystems that supported indexing and placement. The index subsystem managed metadata and object location information for all S3 objects in the region, and AWS said it was necessary for GET, LIST, PUT, and DELETE requests. The disruption also affected other AWS services in us-east-1 that depended on S3.
That is the important part.
The failure was not “just storage.” It was metadata, placement logic, and service dependencies behaving exactly like production-critical architecture — because that is what they were.
Many enterprise platforms carry the same blind spot. Teams classify some layers as operational plumbing, background support, admin logic, or platform internals. Then an incident reveals that those layers are not peripheral at all. They are the thing the entire workload stands on.
A mature architecture becomes more resilient when it stops pretending those subsystems are secondary.
If object metadata, configuration state, workflow orchestration, identity, queue routing, search indexes, or policy engines are required for core operations, they are not support systems. They are part of production.
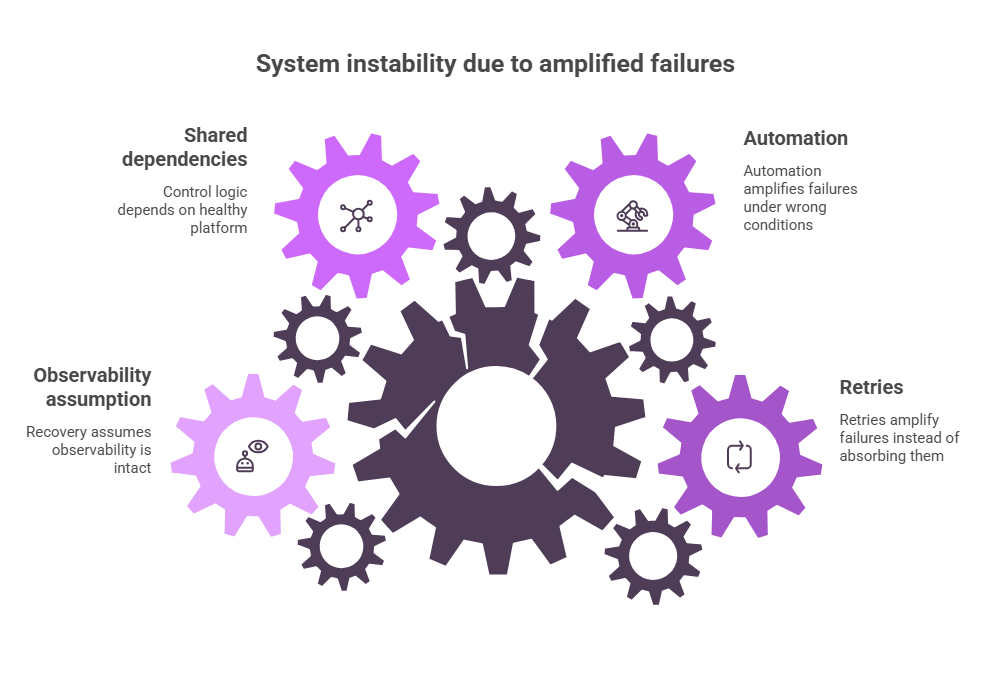
2. Retries and automation can amplify a failure instead of absorbing it
AWS’s December 2021 us-east-1 event is useful for a different reason. AWS explained that foundational internal services such as monitoring, internal DNS, authorization services, and parts of the EC2 control plane were hosted on an internal network connected to the main AWS network through networking devices. An automated scaling activity triggered unexpected client behavior, creating a surge of connections that overwhelmed those devices. AWS then said the resulting delays led to more retries and connection attempts, which made the congestion persist, and that real-time monitoring data for AWS operators was immediately impacted as well.
This is one of the most valuable patterns in modern system design.
A system does not need a dramatic primary fault to become unstable. Sometimes the larger issue is the secondary behavior: retries, reconnect loops, failover thrash, health-check storms, queue replays, aggressive autoscaling, or internal remediation routines that assume the rest of the platform is healthy.
In other words, automation is not always a safety mechanism. Under the wrong conditions, it is a force multiplier.
That is why resilience work cannot stop at “add retries” or “increase redundancy.” It has to ask harder questions:
What happens when every client retries at once?
What dependencies are shared by the control logic itself?
What gets noisier under partial degradation?
What recovery behavior assumes observability is still intact?
When those questions are skipped, the system may be designed to amplify stress rather than absorb it.
The most dangerous design assumption is often not that a component will fail. It is that everything around it will continue behaving normally when it does.
If your platform has already accumulated operational complexity, cloud migration pressure, or reliability concerns, this is usually the point where architecture decisions need to slow down and become more explicit.
Our Platform Audit & Roadmap helps leadership teams identify hidden dependencies, failure-amplifying patterns, and sequencing risks before they turn into expensive modernization mistakes.
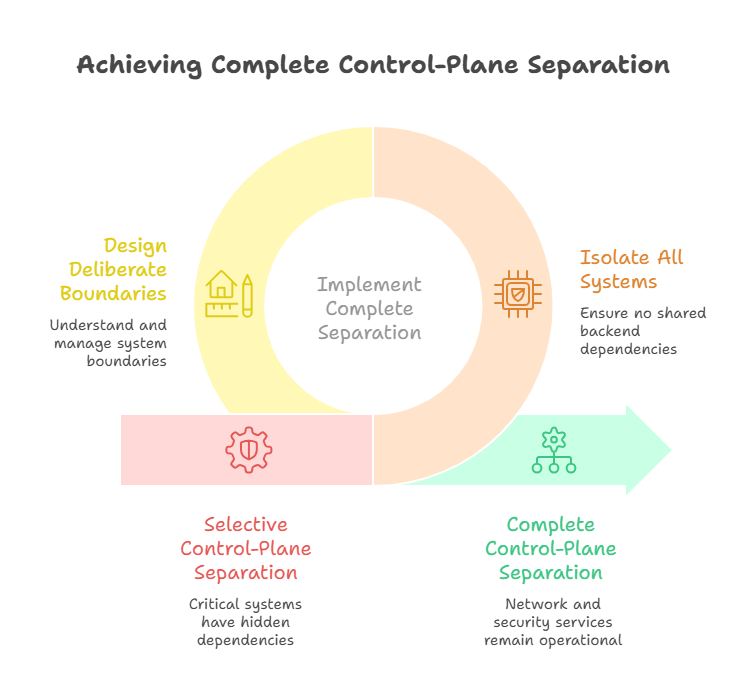
3. Control-plane separation matters — but only if it is complete
Cloudflare’s November 2023 control-plane and analytics outage is instructive because it shows both what worked and what did not. Cloudflare said its network and security services continued to work as expected, even while customers were unable to make changes to services and its control plane and analytics capabilities were disrupted. Cloudflare also said that some critical systems had non-obvious dependencies that made them unavailable, and that some services — especially newer products — had not yet been added to the high-availability cluster intended to prevent this kind of outage.
That is a much more useful lesson than the generic phrase “separate control plane from data plane.”
Because many teams think they have done that when they have only done it partially.
The older core services may be separated. The newer product surfaces may not be. The dashboard may be isolated, but policy propagation still depends on a shared backend. The primary path may fail over, but logging, admin operations, entitlement checks, change controls, or internal tools still share a silent dependency.
That is not real separation. That is selective separation.
And selective separation fails at the worst possible time: when the organization most needs the ability to inspect, change, contain, or recover the system.
For enterprise platforms, the practical question is not “do we have a control plane?” It is “what exactly stops working when the control plane is impaired, and have we designed that boundary deliberately?”
4. Blast radius should be designed around shared dependencies, not vendor labels
It is easy to say “multi-cloud,” “multi-region,” or “multi-zone” and assume the blast radius conversation is settled.
It is not.
AWS explicitly notes in its operational resilience guidance that the 2017 S3 disruption occurred in us-east-1 and not in other AWS Regions, reflecting AWS’s broader design goal of regional isolation. That is useful — but only up to a point.
Google Cloud’s public incident history shows how many managed services can still be affected together when a shared regional or zonal dependency is impaired. In June 2023, Google Cloud reported operational latency across a wide range of services and regions globally, with failures or delays affecting products such as Compute Engine, Cloud SQL, App Engine, Cloud Load Balancing, and others, and with no immediate workaround for most services. In October 2024, Google Cloud also reported intermittent network connectivity in australia-southeast2 affecting a broad set of products including networking, IAM, KMS, Storage, BigQuery, GKE, SQL, and Compute Engine.
That does not mean the providers are weak. It means managed services still share real failure domains.
A strong design therefore asks:
Which components actually share networking paths, control services, identity systems, storage layers, or regional infrastructure?
Which failover plans still depend on a regional control API?
Which “independent” services are only independent on a pricing page, not in a failure event?
This is why blast radius is not primarily a procurement question. It is a dependency-mapping question.
5. Observability and recovery need their own independence
One of the more uncomfortable details in the AWS 2021 event is that the same congestion that disrupted internal services also impaired the availability of real-time monitoring data for AWS’s own operations teams.
Cloudflare’s 2023 postmortem exposed a related issue. It said none of Cloudflare’s observability tools detected that the source of power at the affected data center had changed, and that if Cloudflare had known the facility had failed over to generator power, it would have moved dependent control-plane services out while the site was degraded.
This is the design lesson many teams still underweight.
If your monitoring, change controls, operator access, recovery tooling, or incident diagnostics depend on the same infrastructure that is failing, then you do not have independent recovery capability. You have instrumented coupling.
A resilient system needs more than dashboards. It needs diagnostics, operator paths, and fallback controls that remain available during the classes of failure you claim to withstand.
That usually means treating observability and recovery architecture as first-order design work, not just platform tooling.
What this means for enterprise platform leaders
The practical conclusion is not that cloud is unsafe.
It is that cloud makes abstraction easier, and abstraction can hide fragility until production does the exposing for you.
The most useful response is not provider cynicism. It is sharper system design.
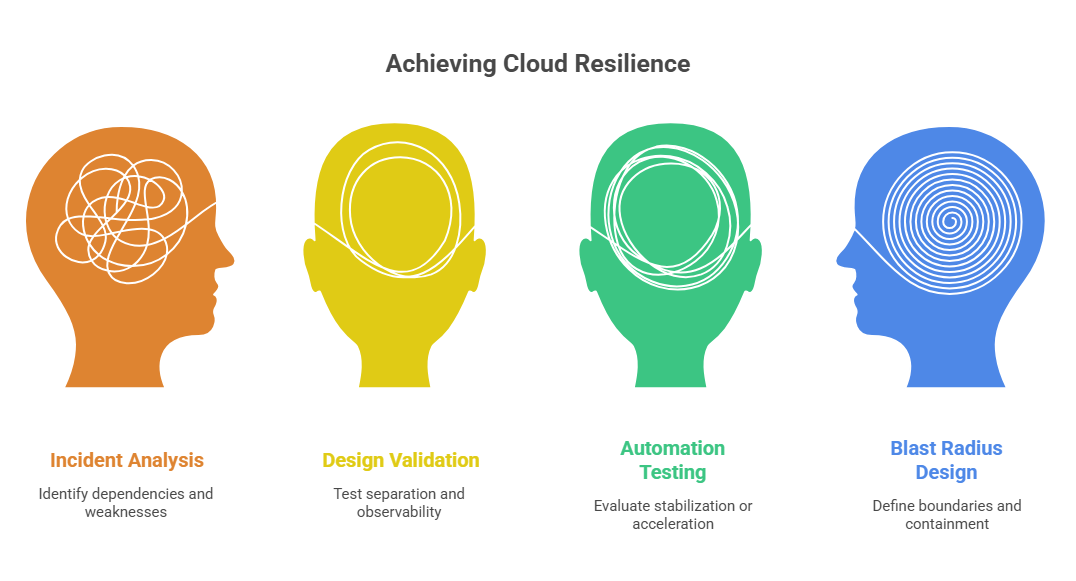
For mature SaaS and operational platforms, that usually means:
identifying which internal subsystems are truly production-critical
separating control, data, and recovery paths more deliberately
testing what retries, automation, and failover do under partial degradation
mapping shared dependencies at the region, service, and workflow level
designing blast-radius boundaries around real coupling, not architecture slogans
making modernization decisions in the order the system can actually tolerate
That is also why many cloud problems are not really migration problems. They are sequencing problems.
Teams move first, then discover the architecture still depends on fragile control layers, hidden regional assumptions, incomplete failover coverage, or recovery tooling that disappears with the incident. By then, the cloud footprint is larger, but the system is not meaningfully more controllable.
That is the wrong kind of modernization.
Final takeaway
Real cloud incidents are useful because they remove the storytelling.
They show what the system depends on when conditions are bad. They show whether separation was real or partial. They show whether observability survives stress. They show whether automation stabilizes the platform or accelerates the failure. And they show whether blast radius was actually designed — or simply assumed.
For enterprise platforms, that is the real lesson.
The question is not whether the cloud is reliable. The question is whether your system is designed to remain legible, controllable, and containable when the cloud behaves imperfectly.
If your team is under pressure to modernize, migrate, or improve reliability, but the actual dependency picture still feels unclear, that is usually a sign to assess the platform before increasing the scope of change.
Our Platform Audit & Roadmap helps CTOs and engineering leaders identify hidden coupling, failure-domain risk, and modernization priorities so the next phase of platform work is more defensible and less disruptive.
We use cookies to enhance your browsing experience, serve personalised ads or content, and analyse our traffic. By clicking "Accept All", you consent to our use of cookies. Cookie Policy