Disaster Recovery vs Disaster Avoidance: A Critical Distinction
April 13, 2026
8
min read
Most teams talk about disaster recovery as though it is the full resilience strategy. It is not. In live production systems, the more important question is often how to reduce the likelihood, scope, and operational cost of failure before recovery ever becomes necessary.
A surprising amount of resilience language in enterprise systems is really recovery language.
Teams discuss backups, failover, incident response, RTOs, RPOs, and continuity plans. Those things matter. They should exist. But they do not answer a more important operational question:
How often are we creating the conditions for avoidable failure in the first place?
That is the distinction between disaster recovery and disaster avoidance.
Recovery asks how the organization responds after something has gone badly wrong.
Avoidance asks what architectural, operational, and delivery decisions reduce the probability, blast radius, and downstream cost of failure before it happens.
In mature platforms, that distinction matters more than many teams admit. A company can have polished recovery documentation and still operate a system that fails too easily, changes too dangerously, and accumulates fragility faster than it can manage. That is not resilience. It is preparedness layered over avoidable instability.
This is one reason enterprise SaaS modernization has to be treated as a risk discipline, not just a technical upgrade program. The goal is not only to recover well when production breaks. It is to reduce the number of ways production can break under normal pressure.
The Mistake Most Teams Make
The common mistake is not that teams invest in disaster recovery.
The mistake is treating recovery as the primary proof of operational maturity.
Recovery is easier to document. It is easier to discuss in governance meetings. It is easier to convert into policy language. It is easier to audit. A recovery plan can be written, reviewed, and approved without forcing the organization to confront deeper questions about architecture, release discipline, dependency mapping, and delivery behavior.
Disaster avoidance is harder.
It forces uncomfortable examination of how change actually moves through the platform. It raises questions about brittle integrations, weak rollback paths, hidden coupling, unclear service boundaries, poor observability, inconsistent operational ownership, and deployment habits that work until they suddenly do not.
That is why many organizations end up with a resilience posture that sounds stronger than it is. They can explain what happens after a critical failure, but they cannot explain why their platform keeps approaching one.
This is especially visible in legacy SaaS modernization, where operational danger often comes less from a single catastrophic event and more from repeated exposure to fragile releases, undocumented dependencies, and architecture that has drifted far beyond its original assumptions.
What Disaster Recovery Actually Covers
Disaster recovery is still necessary. It should not be minimized.
Some failures cannot be designed away completely. Regional outages, provider failures, data corruption events, ransomware scenarios, infrastructure loss, and severe operational incidents all require a recovery posture.
Recovery planning is about survivability. It covers questions such as:
- How quickly can service be restored?
- What data loss is tolerable?
- How are backups validated?
- What systems fail over automatically?
- Which operational dependencies must be restored first?
- How are customers, internal teams, and stakeholders informed?
These are serious questions. But they sit downstream of a different question:
Why is the system exposed to so much avoidable operational danger in the first place?
If teams only invest in recovery, they are effectively accepting a high-risk operating model and optimizing the cleanup.
What Disaster Avoidance Actually Means
Disaster avoidance is not a promise that nothing will ever fail.
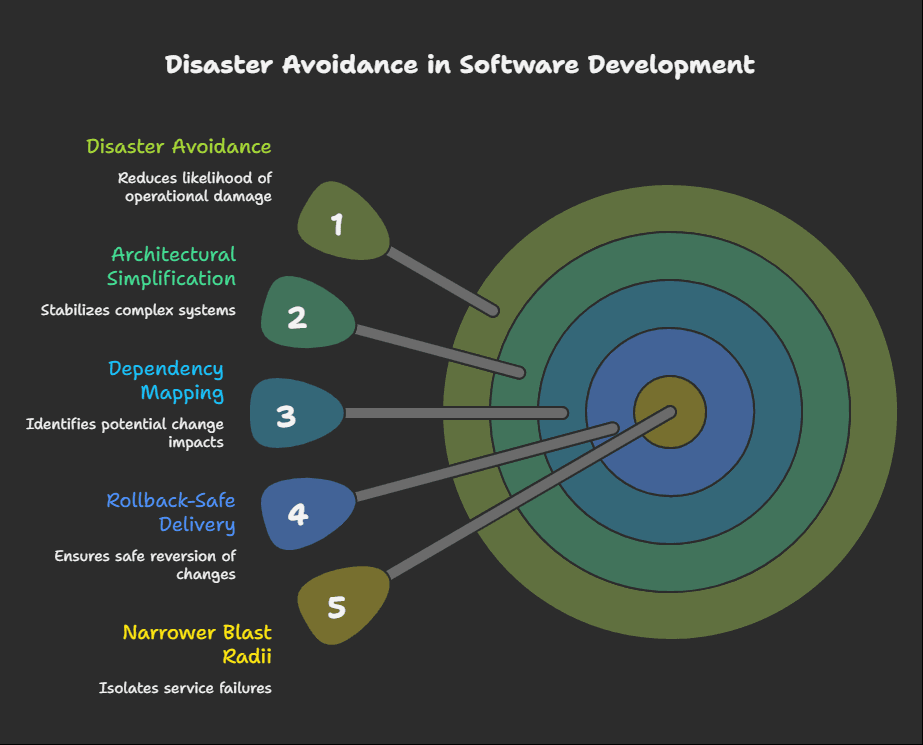
It is a deliberate effort to reduce the likelihood that ordinary platform change becomes extraordinary operational damage.
That usually includes:
- architectural simplification where complexity has become unstable
- dependency mapping before major change
- rollback-safe delivery patterns
- narrower blast radii between services and integrations
- stronger validation before production release
- clearer operational ownership
- better observability around fragile workflows
- controlled sequencing of modernization work
- reducing manual processes that quietly introduce error under pressure
In other words, disaster avoidance lives much closer to the real day-to-day engineering system.
It shows up in engineering practices, in how Duskbyte approaches modernization, and in the discipline of SaaS cloud migration when infrastructure change is treated as an operational decision rather than a symbolic milestone.
A platform that avoids disasters well is usually not the one with the most dramatic recovery story. It is the one where failures are isolated earlier, changes are introduced more carefully, and instability is not allowed to compound unchecked.
Why This Distinction Becomes Critical During Modernization
Modernization is one of the easiest ways to increase disaster risk while telling yourself you are reducing it.
A team decides to replatform a live system, move workloads to AWS, replace part of the data model, introduce event-driven patterns, or layer in automation, integrations, and applied AI. All of those moves can be valid. All of them can also widen the failure surface if sequencing is weak.
This is where recovery language often creates false confidence.
Leaders may say:
We have backups.
We have rollback procedures.
We have incident response.
We have a continuity plan.
But those answers do not address whether the modernization sequence itself is increasing fragility.
A migration with unclear data reconciliation paths is not made safe by a backup policy alone.
A release process with weak environment parity is not made safe by an incident channel.
A brittle third-party integration landscape is not made safe by a failover diagram.
A platform with poorly understood coupling is not made safe by a DR tabletop exercise.
Disaster avoidance forces the team to ask whether the modernization path is making the platform safer to operate, or merely different.
That is also why the strongest modernization programs usually begin with assessment and constraint mapping rather than immediate implementation. Duskbyte’s SaaS Modernization & Cloud Readiness Audit exists for exactly that reason: not to slow action down, but to reduce the chance that a high-cost change program introduces preventable instability.
The Difference in One Sentence
Disaster recovery is about surviving failure.
Disaster avoidance is about operating in a way that makes severe failure less likely, less frequent, and less widespread.
Both matter. But they are not interchangeable.
Where Recovery Is Necessary, and Where It Is Being Used as a Substitute
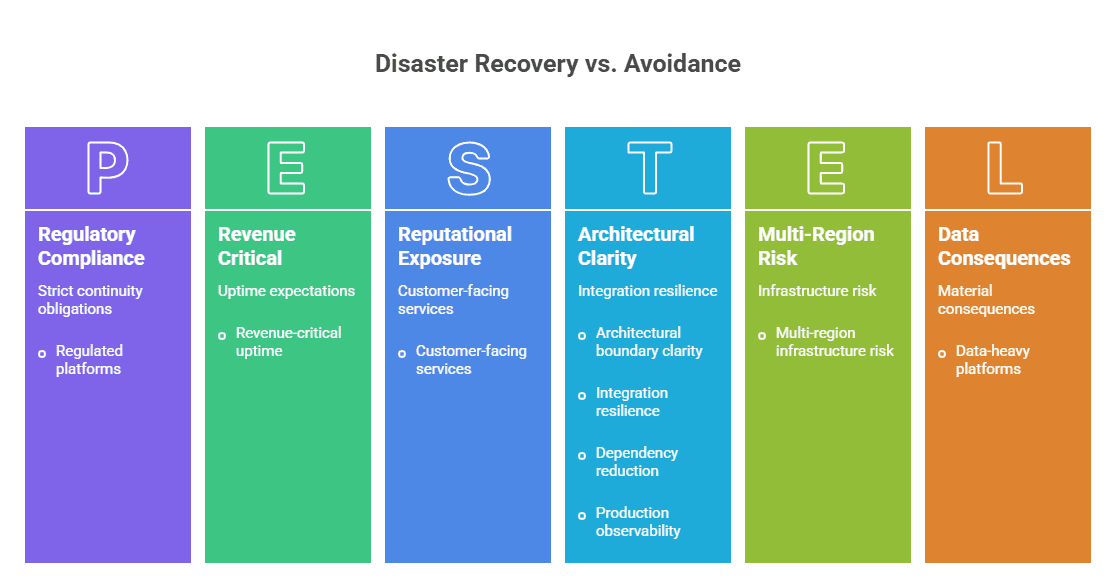
There are environments where disaster recovery should receive heavy investment:
- regulated platforms with strict continuity obligations
- systems with revenue-critical uptime expectations
- customer-facing services with significant reputational exposure
- data-heavy platforms where corruption or loss has material consequences
- platforms with multi-region or multi-provider infrastructure risk
But even in those environments, recovery becomes a weak substitute when it is used to avoid investment in:
- release discipline
- architectural boundary clarity
- rollback-safe deployment
- integration resilience
- dependency reduction
- operational documentation tied to reality
- production observability
- service ownership
This is often the hidden pattern behind repeated production incidents. The organization keeps strengthening recovery artifacts while leaving the underlying operating model mostly untouched.
Over time, the result is predictable. Incidents do not disappear. They simply become better narrated.
Recovery plans matter. Avoidable disasters matter more.
If your platform already has continuity plans but still feels operationally fragile, the issue may not be recovery readiness. It may be architecture, sequencing, dependency risk, or delivery behavior. Our SaaS Modernization & Cloud Readiness Audit helps teams identify where failure risk is actually being created and what should change first.
What Disaster Avoidance Looks Like in Practice
In practice, disaster avoidance usually looks less dramatic than teams expect.
It is not a branded initiative. It is not a single tooling purchase. It is rarely one heroic redesign. It is a pattern of decisions that steadily reduce operational exposure.
That can include:
1. Designing smaller failure domains
Not every issue should have the ability to become a platform-wide event. Better service boundaries, better queueing behavior, better data partitioning, and more careful integration design reduce the chance that one failure propagates everywhere.
2. Sequencing modernization around risk, not enthusiasm
Not every important improvement should happen first. The right first step is often the one that creates clearer operating conditions for everything that follows. That may mean stabilizing deployment, improving observability, or isolating fragile dependencies before attempting broader architecture change.
3. Treating rollback as a design requirement
A rollback plan written after implementation is weaker than a change strategy designed to be reversible from the start. Avoidance depends on reversibility because safe systems allow controlled retreat before damage expands.
4. Reducing hidden dependency concentration
Many preventable incidents come from the same root condition: too many important behaviors rely on components, people, or integrations that the wider team does not fully understand. Avoidance means making those dependencies visible and less fragile.
5. Aligning operations with real system behavior
Runbooks, alerts, escalation paths, and deployment controls should reflect how the platform actually behaves in production. Documents that describe an idealized architecture do not prevent real failures.
This is why how we work matters as much as technical direction. Platforms rarely fail only because of technology choice. They fail because change pressure, system complexity, and weak operational controls interact badly over time.
The Executive Risk of Confusing the Two
For engineering and platform leaders, confusing disaster recovery with disaster avoidance creates a governance problem as much as a technical one.
Recovery metrics can look reassuring. They suggest preparation. They suggest maturity. But if the underlying platform is becoming more fragile, leadership may be operating with false confidence.
That creates three executive risks.
First, modernization initiatives get approved without a realistic view of operational exposure.
Second, recurring incidents are interpreted as bad luck instead of system-pattern failures.
Third, delivery pressure remains high while the platform’s tolerance for change quietly drops.
This is one reason articles like Why Most SaaS Rewrites Fail remain relevant. Large failures in mature platforms are rarely caused by a single missing document. They are usually caused by accumulated assumptions, incomplete understanding, weak sequencing, and change programs that outpace system reality.
Questions Leaders Should Ask
A useful way to test whether the organization is over-indexing on recovery is to ask:
Do we know which parts of the platform are most likely to create severe incidents, or only how we would respond afterward?
Are we reducing dependency risk, or just documenting escalation paths around it?
Can we roll back meaningful changes safely, or do we mostly rely on hope and speed?
Have we narrowed blast radius in the last 12 months, or widened it through modernization pressure?
Do our recovery plans reflect rare catastrophic scenarios, while our actual incidents come from routine releases, brittle integrations, and ordinary operational drift?
If those questions are difficult to answer, the issue may not be insufficient disaster recovery planning. It may be insufficient disaster avoidance discipline.
The More Useful Resilience Standard
A better resilience standard for live systems is not:
Can we recover from a severe failure?
It is:
Are we systematically reducing the conditions that make severe failure likely?
That is a higher bar. It requires more judgment. It also produces a healthier platform.
In real operating environments, the most valuable resilience work is often not the work that helps the organization respond heroically. It is the work that makes heroics necessary less often.
That is the deeper distinction.
Disaster recovery protects the business when things go wrong.
Disaster avoidance improves the odds that fewer things go wrong, that failures stay contained when they do, and that modernization does not become its own source of disruption.
For serious platforms, both are required.
But only one of them improves day-to-day survivability.
Need clarity on where your platform is actually exposed?
f your team is discussing recovery, migration, modernization, or resilience but the real operating risk still feels unclear, start with structured assessment. Duskbyte helps engineering leaders evaluate platform fragility, modernization sequencing, dependency risk, and delivery controls before major change. Explore our modernization approach, review how we work, or start with a SaaS Modernization & Cloud Readiness Audit.