Cloud architecture is often discussed as a scale problem.
In mature systems, it is usually a control problem.
Most architectures do not fail because they lacked another managed service, another autoscaling rule, or another abstract best practice borrowed from a conference talk. They fail because the platform was never designed to remain understandable under pressure. It was not designed to degrade predictably when dependencies slow down. It was not designed to contain failure when queues back up. It was not designed to make safe decisions easy during an incident. And it was not designed to let the team change the system confidently while the business continued to rely on it.
That is why enterprise SaaS modernization and SaaS cloud migration should not be framed as infrastructure exercises alone. In live production environments, cloud architecture has to be judged by how it behaves when conditions are no longer normal.
The real question is not whether the architecture looks modern.
The real question is whether it remains legible when the platform is under operational stress.
The mistake most teams make
A surprising amount of cloud architecture is optimized for architecture diagrams before it is optimized for runtime behavior.
On paper, the system looks clean. Services are separated. Managed infrastructure is in place. Components appear loosely coupled. Resilience is implied by the vocabulary around the system more than by the tested behavior inside it.
Then operational pressure arrives.
A downstream service slows. A queue grows faster than workers can clear it. A third-party provider begins timing out intermittently. A deployment touches a path that had not been exercised under realistic production load. Retries begin stacking. Observability fills with noise. Alerts fire across multiple services. The team sees symptoms everywhere, but clarity nowhere.
This is the point where many architectures reveal that they are not truly resilient systems. They are simply distributed systems with more places to hide fragility.
That is also why Duskbyte’s approach places so much emphasis on assessment before execution, rollback-safe change, and phased modernization. Under stress, architecture is not judged by how current the stack appears. It is judged by how well the system contains problems, exposes the real failure path, and supports calm recovery.
Cloud failure is rarely a single failure
When people say a cloud architecture “failed,” they often compress multiple problems into one phrase.
Sometimes they mean the system could not absorb unexpected load without sharp performance degradation.
Sometimes they mean the incident response path became chaotic because ownership and dependency relationships were not clear enough under pressure.
Sometimes they mean the architecture became far more expensive when the platform was stressed, because autoscaling and retries amplified inefficiency instead of containing it.
Sometimes they mean deployments had already become risky enough that the team did not trust itself to make stabilizing changes during the incident.
Sometimes they mean the platform technically stayed alive, but in an operationally degraded state that caused support burden, customer friction, manual intervention, and loss of confidence.
These are not all infrastructure problems. They are system problems.
And system problems do not disappear just because the workloads now run in the cloud.
This is one of the reasons engineering practices matter as much as platform architecture. A cloud environment can give a team powerful primitives. It does not guarantee operational discipline, architectural clarity, or safe delivery behavior.
The cloud often exposes complexity that was already there
A lot of architectural weakness is inherited, not introduced.
Systems that move into cloud infrastructure often carry years of accumulated assumptions with them: tight coupling between services and data flows, brittle deployment paths, hidden operational dependencies, unclear ownership boundaries, unbounded background processing, undocumented recovery steps, and logic that depends on human workarounds rather than controlled system behavior.
That means many cloud architectures do not become fragile in the cloud. They arrive fragile.
The migration simply makes the fragility more visible.
A queueing layer does not remove poor boundary design. Autoscaling does not solve uncontrolled load patterns. A container platform does not eliminate tightly coupled release behavior. Managed databases do not fix poor data access patterns. Event-driven language does not automatically create resilient event handling.
In mature environments, the deeper issue is usually that platform evolution happened faster than platform discipline.
That is exactly why legacy system modernization cannot be treated as a codebase refresh alone. The platform needs architectural and operational correction, not just newer infrastructure.
Stress reveals where the architecture is lying
Weak architecture can survive calm conditions for a long time.
Traffic remains within expected ranges. Teams learn workarounds. Background jobs complete eventually. Small failures are absorbed by experienced engineers who already know where the fragile parts live. Incidents are handled informally, and the platform retains enough functional credibility that leadership assumes the architecture is healthier than it really is.
Stress changes that.
Stress reveals whether service boundaries are actually independent or merely presented that way. Stress reveals whether asynchronous workflows absorb failure or just delay it. Stress reveals whether retries are protective or destructive. Stress reveals whether observability is helping the team reason or simply documenting confusion in real time. Stress reveals whether architecture decisions were made with real operational accountability in mind.
In that sense, operational stress is not just a technical event. It is an architectural truth test.
Where cloud architectures usually start failing first
The first visible symptom is not always the first real weakness.
In practice, cloud architectures under operational stress tend to fail first in a handful of familiar places.
1. Dependency chains that degrade as a group
Many systems appear modular until one dependency begins to slow down.
Then the same hidden truth appears: too many important workflows still depend on synchronous coordination, shared data assumptions, or background steps that were never designed to fail independently.
When that happens, a local slowdown becomes a multi-service problem. Latency spreads. Threads or workers remain occupied too long. Queues rise. Timeouts increase. Retries multiply. Eventually, the system begins to behave like a coupled platform again, even if the architecture diagram suggests otherwise.
That is why strong architecture is not about having many services. It is about having boundaries that remain meaningful when conditions deteriorate.
2. Retry behavior that turns instability into load amplification
Retry logic is one of the most common sources of self-inflicted architectural stress.
A transient failure occurs. Then client requests retry. Background jobs retry. Workers retry. Scheduled processes retry. User actions repeat because the interface does not provide good feedback. What started as one degraded dependency becomes a multiplication pattern.
The architecture then manufactures its own surge.
Under these conditions, the system is not only absorbing failure. It is actively extending it.
Resilient systems need bounded retries, idempotent operations where appropriate, explicit backoff behavior, clear dead-letter handling, and a realistic understanding of when a failed operation should stop trying. Without that discipline, retries become another dependency path rather than a recovery mechanism.
3. Queues and background jobs that hide backlog until it becomes operationally expensive
Queues can be useful isolation mechanisms. They can also be delay mechanisms that postpone visibility.
A lot of teams feel safer once critical work is “off the request path.” That can be true. But it can also create a false sense of resilience if the queue depth, job age, failure rate, retry policy, and downstream throughput are not being reasoned about as part of the overall system.
A queue that is growing quietly is not evidence of health. It may simply be evidence that the architecture is accumulating unresolved work.
Under stress, this matters because delayed processing can create secondary effects: stale data, broken workflows, duplicate operations, support escalations, customer confusion, and burst recovery events when the system tries to catch up too aggressively.
4. Observability that produces telemetry without producing decisions
Many teams have monitoring. Fewer teams have decision-quality visibility.
Under stress, the issue is not whether logs, dashboards, and traces exist. The issue is whether the team can quickly answer the questions that matter:
What actually failed first? What is expanding the blast radius? Which components are now overloaded? Which changes are safe to make? Which changes must not be made during the incident? What should be stabilized before throughput is restored?
When observability is broad but not structured around these decisions, incident response becomes noisy. The team spends valuable time correlating symptoms manually instead of acting from clarity.
This is one reason How We Work and How We Engage matter as much as the stack itself. Safe cloud architecture requires operational judgment embedded into the delivery model, not just tools layered on top of it.
A useful point to stop and reassess
When the architecture is already showing stress signals, the next best move is often not a larger migration plan. It is a clearer understanding of the platform’s real failure modes, dependency relationships, and safe modernization sequence.
Cloud Resilience, Incidents & Operational Risk
Why Most Cloud Architectures Fail Under Operational Stress
April 13, 2026
8
min read
Cloud Risk
Cloud architecture rarely fails in the diagram. It fails during degraded dependencies, retry storms, release friction, ownership confusion, and recovery paths that looked acceptable until the platform had to survive real operational stress.
Cloud architecture is often discussed as a scale problem.
In mature systems, it is usually a control problem.
Most architectures do not fail because they lacked another managed service, another autoscaling rule, or another abstract best practice borrowed from a conference talk. They fail because the platform was never designed to remain understandable under pressure. It was not designed to degrade predictably when dependencies slow down. It was not designed to contain failure when queues back up. It was not designed to make safe decisions easy during an incident. And it was not designed to let the team change the system confidently while the business continued to rely on it.
That is why enterprise SaaS modernization and SaaS cloud migration should not be framed as infrastructure exercises alone. In live production environments, cloud architecture has to be judged by how it behaves when conditions are no longer normal.
The real question is not whether the architecture looks modern.
The real question is whether it remains legible when the platform is under operational stress.
The mistake most teams make
A surprising amount of cloud architecture is optimized for architecture diagrams before it is optimized for runtime behavior.
On paper, the system looks clean. Services are separated. Managed infrastructure is in place. Components appear loosely coupled. Resilience is implied by the vocabulary around the system more than by the tested behavior inside it.
Then operational pressure arrives.
A downstream service slows. A queue grows faster than workers can clear it. A third-party provider begins timing out intermittently. A deployment touches a path that had not been exercised under realistic production load. Retries begin stacking. Observability fills with noise. Alerts fire across multiple services. The team sees symptoms everywhere, but clarity nowhere.
This is the point where many architectures reveal that they are not truly resilient systems. They are simply distributed systems with more places to hide fragility.
That is also why Duskbyte’s approach places so much emphasis on assessment before execution, rollback-safe change, and phased modernization. Under stress, architecture is not judged by how current the stack appears. It is judged by how well the system contains problems, exposes the real failure path, and supports calm recovery.
Cloud failure is rarely a single failure
When people say a cloud architecture “failed,” they often compress multiple problems into one phrase.
Sometimes they mean the system could not absorb unexpected load without sharp performance degradation.
Sometimes they mean the incident response path became chaotic because ownership and dependency relationships were not clear enough under pressure.
Sometimes they mean the architecture became far more expensive when the platform was stressed, because autoscaling and retries amplified inefficiency instead of containing it.
Sometimes they mean deployments had already become risky enough that the team did not trust itself to make stabilizing changes during the incident.
Sometimes they mean the platform technically stayed alive, but in an operationally degraded state that caused support burden, customer friction, manual intervention, and loss of confidence.
These are not all infrastructure problems. They are system problems.
And system problems do not disappear just because the workloads now run in the cloud.
This is one of the reasons engineering practices matter as much as platform architecture. A cloud environment can give a team powerful primitives. It does not guarantee operational discipline, architectural clarity, or safe delivery behavior.
The cloud often exposes complexity that was already there
A lot of architectural weakness is inherited, not introduced.
Systems that move into cloud infrastructure often carry years of accumulated assumptions with them: tight coupling between services and data flows, brittle deployment paths, hidden operational dependencies, unclear ownership boundaries, unbounded background processing, undocumented recovery steps, and logic that depends on human workarounds rather than controlled system behavior.
That means many cloud architectures do not become fragile in the cloud. They arrive fragile.
The migration simply makes the fragility more visible.
A queueing layer does not remove poor boundary design. Autoscaling does not solve uncontrolled load patterns. A container platform does not eliminate tightly coupled release behavior. Managed databases do not fix poor data access patterns. Event-driven language does not automatically create resilient event handling.
In mature environments, the deeper issue is usually that platform evolution happened faster than platform discipline.
That is exactly why legacy system modernization cannot be treated as a codebase refresh alone. The platform needs architectural and operational correction, not just newer infrastructure.
Stress reveals where the architecture is lying
Weak architecture can survive calm conditions for a long time.
Traffic remains within expected ranges. Teams learn workarounds. Background jobs complete eventually. Small failures are absorbed by experienced engineers who already know where the fragile parts live. Incidents are handled informally, and the platform retains enough functional credibility that leadership assumes the architecture is healthier than it really is.
Stress changes that.
Stress reveals whether service boundaries are actually independent or merely presented that way. Stress reveals whether asynchronous workflows absorb failure or just delay it. Stress reveals whether retries are protective or destructive. Stress reveals whether observability is helping the team reason or simply documenting confusion in real time. Stress reveals whether architecture decisions were made with real operational accountability in mind.
In that sense, operational stress is not just a technical event. It is an architectural truth test.
Where cloud architectures usually start failing first
The first visible symptom is not always the first real weakness.
In practice, cloud architectures under operational stress tend to fail first in a handful of familiar places.
1. Dependency chains that degrade as a group
Many systems appear modular until one dependency begins to slow down.
Then the same hidden truth appears: too many important workflows still depend on synchronous coordination, shared data assumptions, or background steps that were never designed to fail independently.
When that happens, a local slowdown becomes a multi-service problem. Latency spreads. Threads or workers remain occupied too long. Queues rise. Timeouts increase. Retries multiply. Eventually, the system begins to behave like a coupled platform again, even if the architecture diagram suggests otherwise.
That is why strong architecture is not about having many services. It is about having boundaries that remain meaningful when conditions deteriorate.
2. Retry behavior that turns instability into load amplification
Retry logic is one of the most common sources of self-inflicted architectural stress.
A transient failure occurs. Then client requests retry. Background jobs retry. Workers retry. Scheduled processes retry. User actions repeat because the interface does not provide good feedback. What started as one degraded dependency becomes a multiplication pattern.
The architecture then manufactures its own surge.
Under these conditions, the system is not only absorbing failure. It is actively extending it.
Resilient systems need bounded retries, idempotent operations where appropriate, explicit backoff behavior, clear dead-letter handling, and a realistic understanding of when a failed operation should stop trying. Without that discipline, retries become another dependency path rather than a recovery mechanism.
3. Queues and background jobs that hide backlog until it becomes operationally expensive
Queues can be useful isolation mechanisms. They can also be delay mechanisms that postpone visibility.
A lot of teams feel safer once critical work is “off the request path.” That can be true. But it can also create a false sense of resilience if the queue depth, job age, failure rate, retry policy, and downstream throughput are not being reasoned about as part of the overall system.
A queue that is growing quietly is not evidence of health. It may simply be evidence that the architecture is accumulating unresolved work.
Under stress, this matters because delayed processing can create secondary effects: stale data, broken workflows, duplicate operations, support escalations, customer confusion, and burst recovery events when the system tries to catch up too aggressively.
4. Observability that produces telemetry without producing decisions
Many teams have monitoring. Fewer teams have decision-quality visibility.
Under stress, the issue is not whether logs, dashboards, and traces exist. The issue is whether the team can quickly answer the questions that matter:
What actually failed first? What is expanding the blast radius? Which components are now overloaded? Which changes are safe to make? Which changes must not be made during the incident? What should be stabilized before throughput is restored?
When observability is broad but not structured around these decisions, incident response becomes noisy. The team spends valuable time correlating symptoms manually instead of acting from clarity.
This is one reason How We Work and How We Engage matter as much as the stack itself. Safe cloud architecture requires operational judgment embedded into the delivery model, not just tools layered on top of it.
A useful point to stop and reassess
When the architecture is already showing stress signals, the next best move is often not a larger migration plan. It is a clearer understanding of the platform’s real failure modes, dependency relationships, and safe modernization sequence.
Need a clearer picture before expanding the scope?
The SaaS Modernization & Cloud Readiness Audit is designed for teams that need to understand what is actually creating operational risk, what can be stabilized first, and how to sequence modernization without increasing blast radius.
It is a practical entry point when cloud conversations are getting expensive, but the underlying system still feels difficult to reason about.
Release fragility is often the hidden architectural problem
A lot of cloud modernization efforts improve hosting but leave change risk mostly untouched.
The platform moves. The release discipline does not.
That leaves teams with newer infrastructure but familiar operational anxiety: cautious deployments, unclear rollback paths, environment drift, fragile migrations, and too much dependence on individual memory during high-risk changes.
This matters because an architecture under stress is not judged only by how it runs. It is judged by how safely it can be changed while it is under strain.
If every deployment feels dangerous, then the architecture is already signaling weak operational control. If rollback is possible only in theory, then the platform is less resilient than it appears. If the team needs heroic intervention to stabilize changes, then architecture and delivery practice are still too tightly entangled.
That is why enterprise software development for live systems cannot be separated from the operational model behind it. In serious production environments, delivery safety is part of system design.
Identity, access, and environment boundaries fail more often than teams admit
Not all cloud stress shows up as latency and throughput.
Some of the most damaging architecture failures emerge through weak environment controls, excessive privilege, inconsistent access boundaries, or ambiguous ownership across accounts, services, and automation layers.
These issues do not always appear dramatic at first. They show up as slowed response, over-broad operational access, accidental production interference, weak separation between testing and real workloads, or architecture that is technically secure enough to pass review but operationally too loose to support safe change at scale.
That is one reason security and access practices should be viewed as part of architecture maturity, not as a separate compliance concern. Under stress, unclear access models and poor environment boundaries make recovery slower, more political, and more error-prone.
Cost blowouts are often architecture signals, not only financial signals
When systems come under stress, cloud cost often becomes part of the discussion very quickly.
That is understandable, but it is easy to misread.
The cost spike is not always the root problem. Often it is the architectural symptom.
Unbounded retries, inefficient scale-out behavior, expensive synchronous dependencies, poorly controlled data movement, and recovery mechanisms that overcompensate can all convert instability into cost growth. In those situations, cost optimization alone does not solve the underlying issue. It simply trims the symptom while the architectural pressure remains.
A better question is: what system behavior becomes disproportionately expensive when the platform is stressed?
That question usually leads closer to the real problem.
Many architectures are optimized for velocity, not survivability
Some platforms are not fragile because they are old.
They are fragile because they were optimized around delivery speed without enough attention to failure isolation, reversibility, operational tolerance, or ownership clarity.
That creates a recognizable pattern over time.
The system keeps evolving. The integration surface keeps growing. Background processing becomes more important. Cloud spend rises. Operational understanding becomes more uneven across the team. Making changes becomes slower because the architecture is harder to trust.
At that stage, leadership often starts reaching for bigger answers: replatforming, decomposition, service sprawl, or a broad rewrite. But the problem is often more specific than that. The architecture has lost control at the points where stress exposes it.
That is why the relevant Duskbyte insight on why most SaaS rewrites fail matters here. Starting over does not remove the burden of understanding runtime behavior, failure patterns, delivery risk, and dependency reality. It often increases it.
What strong cloud architecture actually does
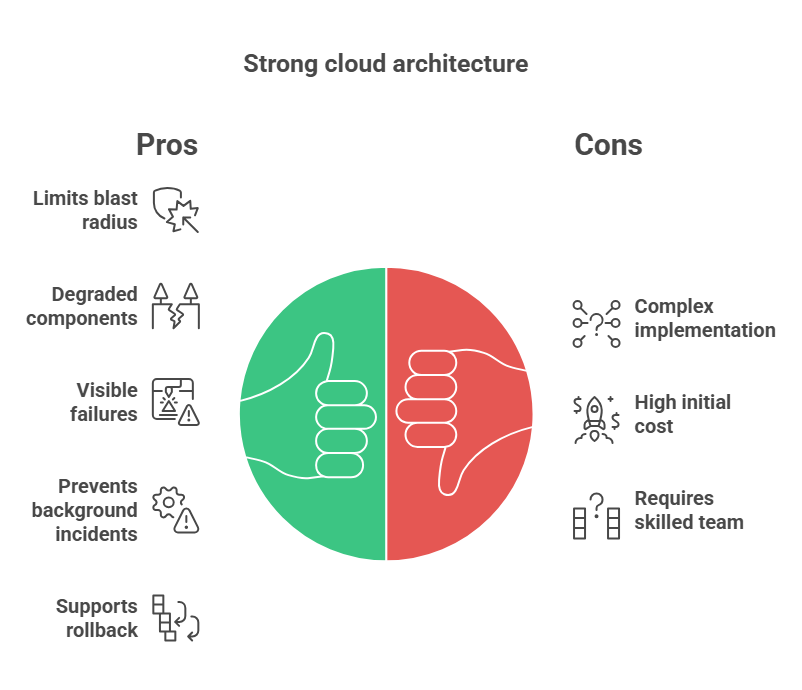
Strong cloud architecture is not simply cloud architecture with more services, more tooling, or more abstraction.
It does a few harder things well.
It limits blast radius. It allows degraded components to stay degraded without collapsing the rest of the platform. It makes important failure paths visible early. It prevents background processing from quietly becoming a second incident. It supports rollback without theater. It makes ownership legible. It gives operators enough system clarity to act with discipline rather than guesswork. It distinguishes between inconvenience and business-critical failure.
That is a much more useful standard than asking whether the architecture is sufficiently “cloud native.”
Because the real test is not whether the platform can be described elegantly.
The real test is whether it can stay controllable when normal assumptions stop holding.
A better framework for evaluating operational stress
If a team is trying to decide whether its cloud architecture is becoming operationally dangerous, these questions are usually more useful than broad maturity scoring:
When one dependency slows down, which workflows actually degrade with it?
Which parts of the platform can fail independently, and which still fail together?
What does the retry model do under partial outage conditions?
Where does work accumulate when throughput drops?
Which operational paths depend too heavily on institutional memory?
Can the team explain the rollback path for the last few meaningful releases?
During incidents, do dashboards reduce ambiguity or simply confirm widespread pain?
Which parts of the system become most expensive when conditions are unstable?
Are access boundaries and environment controls making recovery safer or more fragile?
Has cloud migration improved operational control, or mainly changed where existing fragility now lives?
These questions are valuable because they shift the conversation from generic cloud posture to architectural behavior under pressure.
The real goal is not cloud maturity. It is operational control.
For mature systems, cloud architecture should ultimately be judged by whether it improves operational control.
Does it make the platform easier to reason about? Does it make failure more containable? Does it make safe change more realistic? Does it give leadership and engineering teams more clarity about what to modernize next? Does it reduce the chance that a small failure becomes a broad operational event?
If the answer is no, then the architecture may be current in form while still weak in practice.
That distinction matters.
Because under operational stress, the platform is no longer being tested as a diagram, a migration plan, or a tooling choice.
It is being tested as a system of decisions.
And most failures begin when the system becomes harder to see, harder to reason about, and harder to change safely at exactly the moment the business needs the opposite.
Clarify the stress points before expanding the architecture
If your platform is already showing signs of cloud cost pressure, deployment anxiety, brittle integrations, unclear recovery behavior, or incidents that seem larger than their triggering cause, that is usually the moment to slow the architecture conversation down and make the failure modes explicit.
Request a SaaS Modernization & Cloud Readiness Audit
The SaaS Modernization & Cloud Readiness Audit helps leadership teams assess architectural risk, dependency sprawl, release fragility, and cloud readiness before larger changes make the platform harder to control.
We use cookies to enhance your browsing experience, serve personalised ads or content, and analyse our traffic. By clicking "Accept All", you consent to our use of cookies. Cookie Policy